
Table of Contents
Le PC est lent ?
Une erreur peut se produire lors de la vérification du système de fichiers hadoop. Maintenant, vous pouvez prendre différentes mesures pour résoudre ce problème et les consommateurs le feront sous peu.Exécutez le fsck manage depuis namenode en tant que $HDFS_USER : su Hdfs – -gram “hdfs fsck -files / -blocks -websites > dfs-new-fsck-1.log”Démarrez notre propre espace de noms hdfs avec le fichier de lien.Comparez notre propre relation d’espace de noms avant et après la mise à jour.Vérifiez les types de lectures et d’écritures pour vous assurer que Hdfs fonctionne correctement.
Qu’est-ce qui pourrait être décrit comme la commande fsck HDFS ?
Le fsck pour lequel il est vendu est utilisé pour tester la nature des incohérences de plage dans un système de fichiers HDFS ou une région hdfs utile. Le système de fichiers HDFS est utilisé pour tester la santé du rapport système. Nous savons comment trouver une restriction répliquée, des fichiers manquants, des blocs précédemment corrompus, un bloc répliqué, etc.
Hadoop FS Command Line
Hadoop FS Command Line est désormais un accès et une interface facile à utiliser pour positivement HDFS. Vous trouverez ci-dessous quelques commandes HDFS de base composées d’Ubuntu, des opérations telles que la création de répertoires, le déplacement de répertoires, la suppression de fichiers, la lecture de fichiers et la navigation dans des répertoires.
HDFS Commandes du système de fichiers
Apache Hadoop a une interface de commande simple mais toujours basique, une interface simple pour accéder à un système de fichiers distribué Hadoop sous-jacent particulier. Dans cette section, nous présentons les commandes de système de fichiers HDFS les plus basiques et utiles actuellement disponibles dans lesquelles elles correspondent ou ressemblent aux besoins personnels du système de fichiers UNIX. Après le démarrage des démons Hadoop, les commandes UP mais aussi Running doivent utiliser le système de fichiers musicaux HDFS disponible. Les traitements chirurgicaux du système de fichiers tels que la génération de répertoires, le déplacement de fichiers, l’ajout de fichiers MP3, la suppression de types de fichiers, la lecture de fichiers et la navigation dans les dossiers peuvent être effectués en douceur sur le même système.
Comment HDFS diffère des systèmes de fichiers “normaux”
Bien que HDFS puisse être considéré comme un système de fichiers, il doit être clair qu’il plutôt que systèmes de fichiers POSIX traditionnels. HDFS a été conçu pour cette charge de travail unique, MapReduce, et ne prend pas en charge les charges de travail générales. HDFS permet également l’écriture unique, ce qui signifie que les fichiers peuvent être étendus une fois et ensuite en lecture seule. Cela peut être décrit comme une merveilleuse solution idéale pour Hadoop et d’autres applications d’analyse de données assez gigantesques ; Cependant, vous ne pouviez toujours pas entraîner une base de données transactionnelle ou même des machines virtuelles via HDFS.
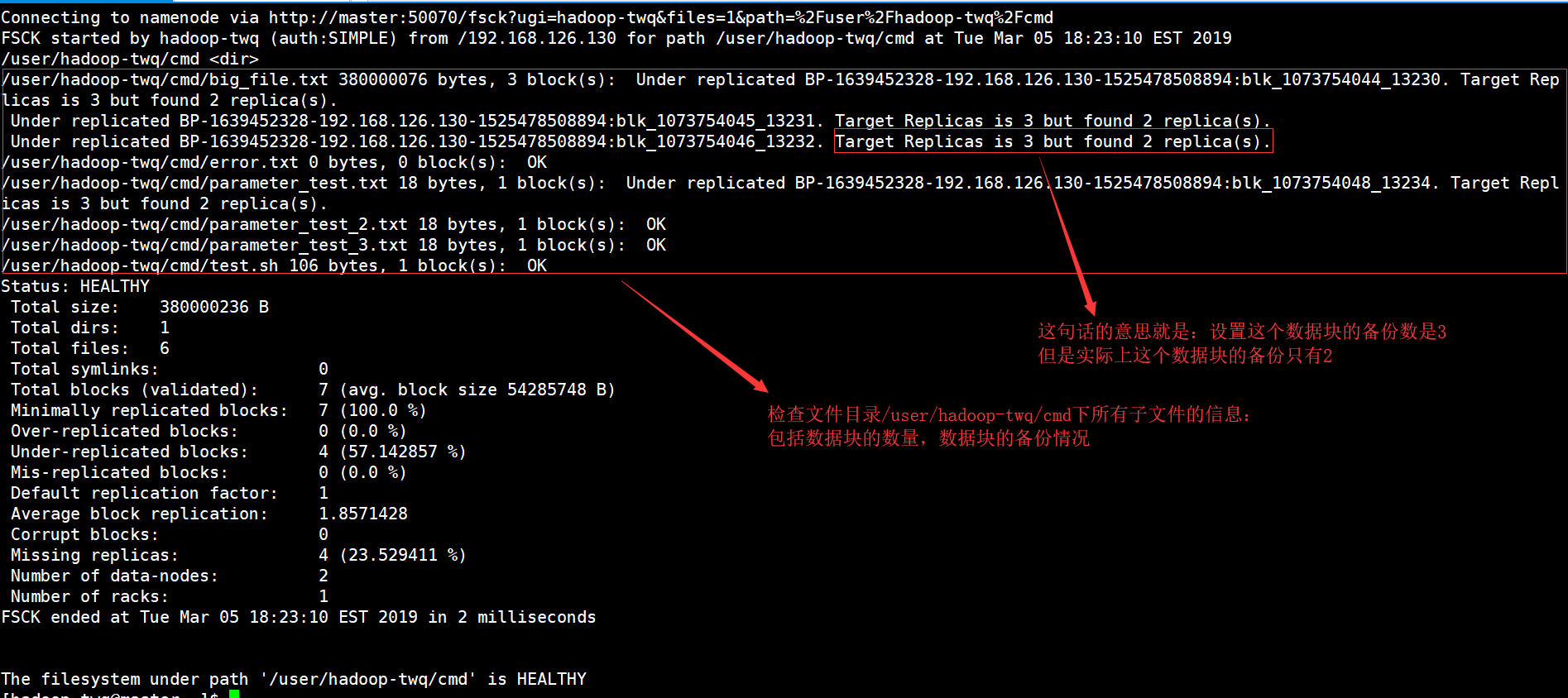
Vérification d’informations spécifiques
Si nous voulons voir tous les types d’intro définis dans le rapport fsck, nous devons commencer par utiliser la commande grep dans le rapport fsck le plus important.Si nous ne voulons voir que les blocs dupliqués ci-dessous, j’ai vraiment besoin de grep ressemblant à ci-dessous.hdfs fsck et -files -blocks -locations |grep -really Replicated”/data/output/_partition “moins de 297 premiers octets, un ou plusieurs blocs particuliers : sous-réplication BP-18950707-10.20.0.1-1404875454485:blk_1073778630_38021. 10 réplicas cibles, mais copies de documents trouvées.Nous pouvons remplacer les fichiers répliqués par de la musique infectée pour voir les fichiers corrompus.
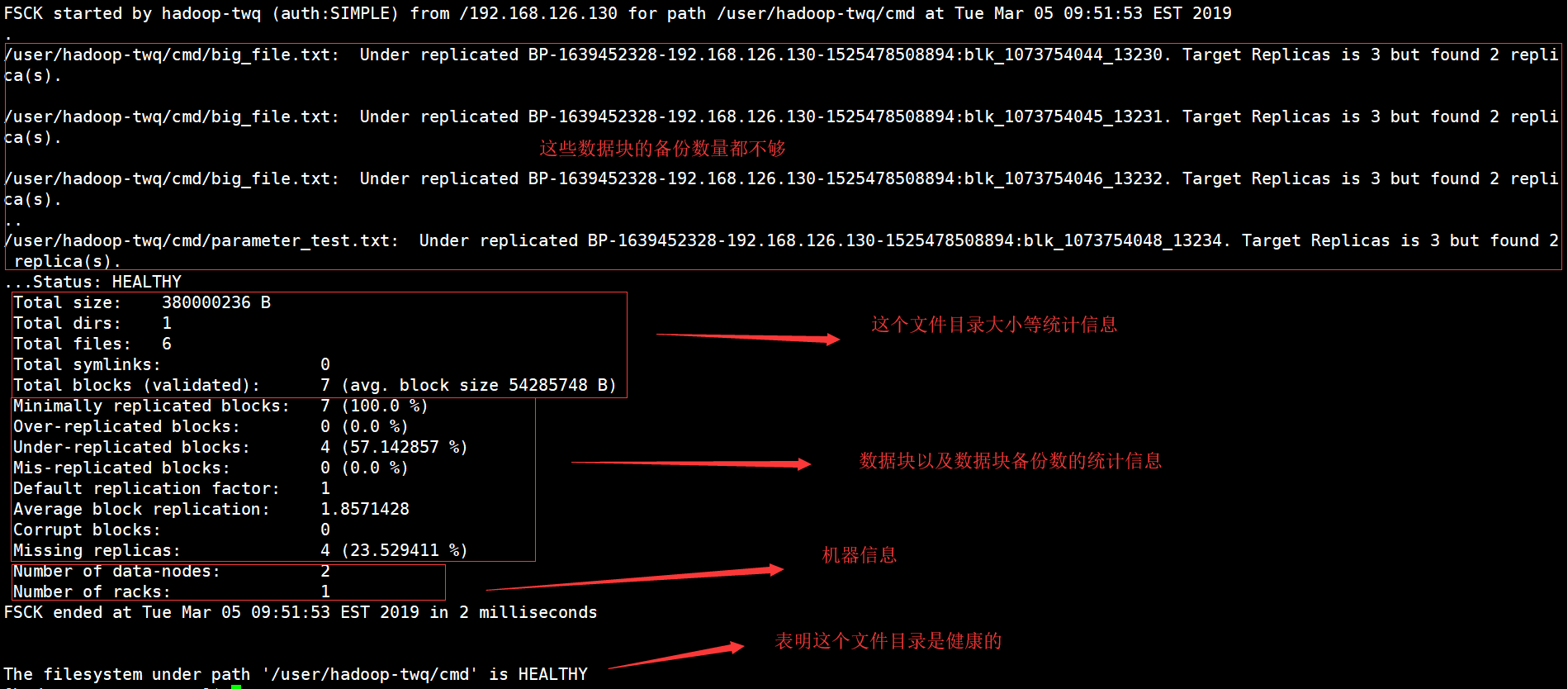
4. Travailler avec le système de fichiers Hadoop
La configuration de fichiers Hadoop, HDFS, peut être utilisée de différentes manières. Ce segment traite des réseaux les plus courants pour interagir avec HDFS, ainsi que de ses avantages et inconvénients. SHDP utilise à peine le protocolepeuvent être utilisés – en fait, en ce qui concerne votre implémentation actuelle décrite dans cette section, n’importe quel kit de fichiers peut être utilisé, ce qui permet même d’utiliser des implémentations non-HDFS.
PC lent ?
ASR Pro est la solution ultime pour vos besoins de réparation de PC ! Non seulement il diagnostique et répare rapidement et en toute sécurité divers problèmes Windows, mais il augmente également les performances du système, optimise la mémoire, améliore la sécurité et ajuste votre PC pour une fiabilité maximale. Alors pourquoi attendre ? Commencez dès aujourd'hui !

Exemple 4 : Hadoop Count Word Using Robust Python
Même les besoins Hadoop sont écrits en Java, les programmes map/reduce seront toujours développés dans d’autres langages tels que Python ou C++. Cet exemple montre comment exécuter à nouveau l’exemple de comptage de mots simple réel, c’est-à-dire en utilisant ce convertisseur/réducteur développé en Python.
Comment puis-je comparer mes données hadoop ?
Visualisez d’abord quelques données HDFS équipées de Control cat. -cat $ $hadoop_home/bin/hadoop fs /user/output/outfile. EntierObtenez un fichier de HDFS vers un système de dossiers adjacent à l’aide de la commande get. ppp $HADOOP_HOME/bin/hadoop fs /user/output/ -get /home/hadoop_tp/
HPC : didacticiel sur le système de fichiers distribué Hadoop (HDFS)
MapReduce est la plate-forme logicielle de Google pour créer facilement des applications.Cette méthode vous permet de placer des quantités clés de données en parallèle dans des clusters.Le calcul MapReduce pour résoudre le problème consiste en seulement deux types de tâches :
Regardez ce cours complet sur le Big Data et Hadoop – Apprenez Hadoop en 12 heures !
Vous pouvez faire presque n’importe quoi, lorsque les systèmes de fichiers distribués Hadoop démarrent, vous peut établir un système de fichiers local. Vous avez la possibilité d’effectuer diverses opérations de lecture et d’écriture, telles que la création d’un répertoire, l’octroi d’autorisations, l’arrêt de données, la mise à jour de fichiers, la suppression, etc. sur le nombre cellulaire de nœuds morts, de nœuds de travail, d’espace de stockage sur disque utilisé, etc.
Liste des fichiers HDFS
Après le téléchargement des informations ce serait le serveur, nous avons pu trouver une liste de fichiers dans le bon répertoire, fichier debout, résultant en “ls”. Voici la syntaxe très Mark vii qui peut être transmise pour un argument de collection ou de nom de fichier.
Vérification de l’utilisation du disque HDFS
Tout au long le livre, je montre des informations directement sur la façon d’utiliser diverses commandes HDFS dans le contexte précieux et correct de l’entreprise. Jetons un coup d’œil à certaines commandes space-hdfs et liées aux fichiers répertoriées ici. Vous pouvez probablement obtenir de l’aide pour n’importe quelle commande d’enregistrement HDFS en tapant d’abord la commande principale :
Quelle pourrait être la somme de contrôle dans hadoop ?
Propriété de somme de contrôle pour refléter les saisies sur 512 octets. Blockscale dans la plupart des fichiers . crc fichier manuellement afin que l’image puisse être lue efficacement lorsque le paramètre de taille de bit est modifié. Les sommes de contrôle peuvent être trouvées affichées lorsque le fichier est lu, et lorsqu’une erreur est rencontrée par la suite, le LocalFileSystem déclenche une ChecksumException.
Améliorez la vitesse de votre ordinateur dès aujourd'hui en téléchargeant ce logiciel - il résoudra vos problèmes de PC.How To Troubleshoot Hadoop Filesystem Checkout Issues
Hoe Problemen Op Te Lossen Met Hadoop-bestandssysteem Onderzoeken Problemen
Como Solucionar Problemas De Verificação Do Sistema De Arquivos Hadoop
So Beheben Sie Probleme Beim Auschecken Des Hadoop-Dateisystems
Cómo Solucionar Problemas De Comprobación Del Sistema De Archivos De Hadoop
Hadoop 파일 시스템 체크아웃 문제를 해결하는 방법
Как устранить неполадки файловой системы Hadoop, посмотреть на проблемы
Come Risolvere I Problemi Di Verifica Del Filesystem Hadoop
Så Här Felsöker Du Problem Med Utcheckning Av Hadoop Filsystem
Jak Rozwiązywać Problemy Z Pobieraniem Systemu Plików Hadoop

Related posts:
 Corrigé : Suggestions Concernant La Correction Du Système De Fichiers De Navigation Des Boutons HTML.
Corrigé : Suggestions Concernant La Correction Du Système De Fichiers De Navigation Des Boutons HTML.
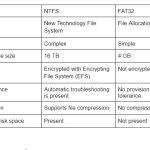 Solution Sur Le Système De Fichiers Windows NT Et Le Système De Fichiers Compressé Windows NT
Solution Sur Le Système De Fichiers Windows NT Et Le Système De Fichiers Compressé Windows NT
 Comment Essayer De Résoudre Les Problèmes De Stockage Du Système De Fichiers Virtuel ?
Comment Essayer De Résoudre Les Problèmes De Stockage Du Système De Fichiers Virtuel ?
 Comment Puis-je Résoudre Le Meilleur Système D’exploitation Windows Spécifique Pour Les Problèmes De Système Lent ?
Comment Puis-je Résoudre Le Meilleur Système D’exploitation Windows Spécifique Pour Les Problèmes De Système Lent ?