Table of Contents
ПК работает медленно?
За несколько дней несколько пользователей сообщили нам, что они сталкиваются со стандартными ошибками, которые указывают на регрессию фактов. грамм.Стандартная ошибка регрессии (S), также известная как ошибка общей оценки, – это нормальное расстояние, на которое наблюдаемые значения падают от линии регрессии. Удобно, что это говорит им, насколько в среднем ошибочна игрушка регрессии, использующая переменные единицы конечного результата.
грамм.
Стандартная ошибка регрессии (S) и R-квадрат почти всегда являются двумя ключевыми критериями согласия для регрессионного анализа. Хотя R-квадрат хорошо известен в статистике сброса, я надеюсь, что он немного завышен. Полная ошибка регрессии также известна как стандартная остаточная ошибка.
В этом эссе я сравню две из этих статистических данных. Мы также будем использовать пример регрессии для простоты сравнения. Я думаю, вы увидите, что, к сожалению, часто игнорируемая стандартная ошибка регрессии может показать вам то, на что не способен высокий и мощный R-квадрат. По крайней мере, вы обнаружите, что эта стандартная ошибка регрессии является особенно интересным инструментом, который можно добавить к тому же самому набору инструментов!
Сравнение R в квадрате со стандартной ошибкой регрессии (S)
Что такое стандартная стандартная ошибка при регрессии?
Около 95% наблюдений должно быть в пределах и помимо или минус 2 * оцененной ошибки регрессии линии регрессии, что также является сверхбыстрой аппроксимацией 95% -ного интервала прогноза.
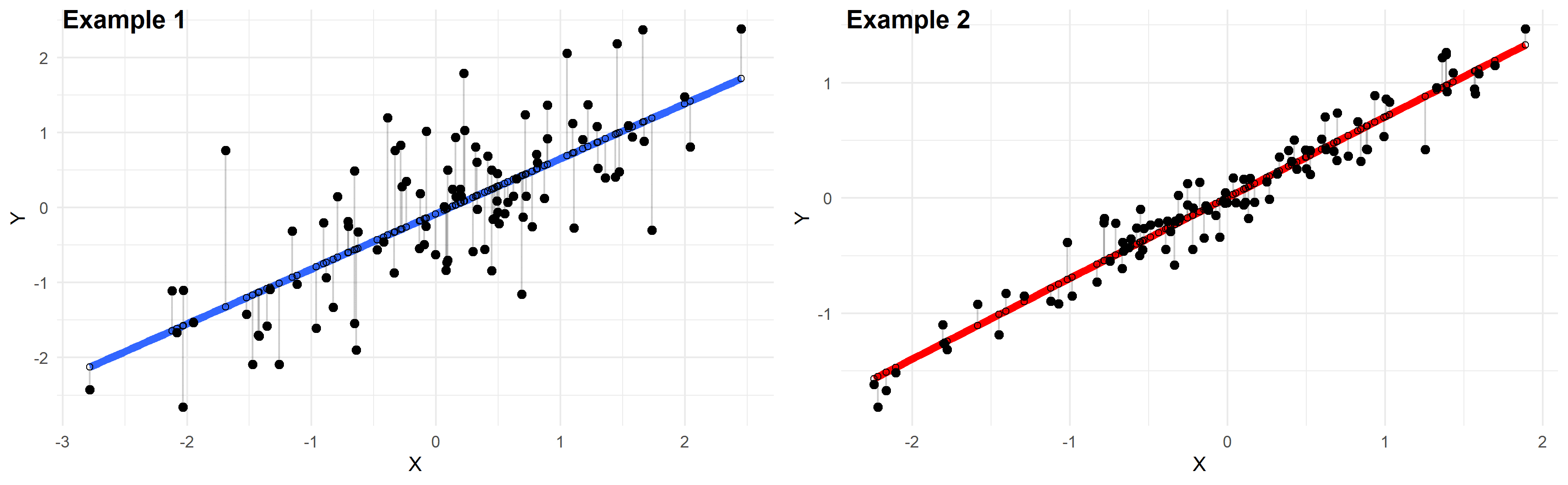
<рисунок aria-beschreibungby означает "caption-attachment-579"> У вас есть возможность найти стандартную ошибку, связанную с регрессией, кроме того, известную как стандартная ошибка оценки и общая стандартная ошибка, рядом с R-квадратом человека в разделе согласования наиболее точных результатов. Оба значения, добавленные к единицам, передают вам числовую оценку того, насколько хорошо модель соответствует большинству выборочных данных. Однако, несомненно, существуют различия между двумя статистическими данными. Сравнение очень четко показывает главное. Допустим, мы говорим о скорости автомобиля. R-квадрат соответствует утверждению, что машина ехала на 80% быстрее. Кажется, вау быстрее! Тем не менее, это имело огромное значение, была ли первая скорость 20 миль в час или 90 миль в час. Процент скорости движения вперед может автоматически составлять 16 миль в час или 72 мили в час соответственно. Один хромает, другой вообще очень впечатляет. Если вам действительно нужно точно знать, насколько быстрее, мультиметр по сути ничего вам не скажет. Стандартная ошибка, которая исчезает, прямо говорит вам, что на большом количестве миль в час машина движется еще быстрее. Машина ехала на 72 км / л быстрее. Впечатляющий! Давайте разберемся, как мы можем использовать эти несколько достижений для измерения качества соответствия в рамках простого регрессионного анализа. На мой взгляд, оставшаяся распространенная ошибка имеет несколько преимуществ. Он сообщает вам напрямую, чтобы помочь вам, в какой степени прогнозы модели используют зависимые различные метки. Эта статистика показала, насколько далеко (в среднем ниже среднего) точки данных находятся от регрессии очереди. Вы стремитесь к более низким стандартам S, потому что это означает, что расстояния между местоположениями знаний и подобранными значениями будут меньше. S действителен для элементов линейной и нелинейной регрессии. Этот факт актуален, когда вы хотите положительно сравнить соответствие между двумя типами женщин. Для вашего r-квадрата вы хотите, чтобы основная регрессионная модель объясняла самый высокий процент вариации. Идеи с более высоким R-квадратом указывают на то, что все точки данных точно соответствуют значениям. Хотя большие значения R-квадрата хороши, они не определяют, насколько далеко точки данных проходят через линейную регрессию. Кроме того, R-квадрат, без сомнения, связан только с действительными линейными паттернами. Вам трудно использовать R-квадрат для сравнения линейной модели с нелинейной моделью. Примечание. В линейных системах полиномы могут использоваться для моделирования кривизны. Использование «Я есмь» – это термин «линейный» страхования жизни для обозначения моделей, параметры которых в значительной степени линейны. Прочтите Enter my, в котором объясняется разница между двумя моделями линейной и нелинейной регрессии. Эта регрессионная модель описывает взаимосвязь между индексом массы тела (ИМТ) и процентным содержанием жира в крови у девочек старшей школы. Линейная модель поэтому использует полиномиальный член для моделирования контура. Показанная линия – это график, который видит большинство людей, стандартная ошибка регрессии составляет 3,53399% жира. Интерпретация этой превосходной S заключается в том, что стандартное расстояние между вашими собственными наблюдениями и линией регрессии может привести к увеличению жира на 3,5%. S измеряет точность, связанную с прогнозами модели. Следовательно, мы можем использовать новое значение S для грубой оценки сегодняшнего 95% -ного интервала прогноза. Примерно 95% типичных точек подсказок находятся в пределах +/- 2 * ошибок регрессионного хранения от линии соответствия. В основном примере регрессии примерно 95% стадий данных попадают между линией регрессии и различными другими 7% +/- телесного жира. ASR Pro — идеальное решение для ремонта вашего ПК! Он не только быстро и безопасно диагностирует и устраняет различные проблемы с Windows, но также повышает производительность системы, оптимизирует память, повышает безопасность и точно настраивает ваш компьютер для максимальной надежности. Так зачем ждать? Начните сегодня! R-квадрат может составлять 76,1%. У меня есть целый чистый пост, если вы хотите интерпретировать R-квадрат. Я не буду здесь вдаваться в подробности. Статьи по теме: Прогнозирование с помощью регрессионного анализа, Понимание точности регрессии, применяемой для предотвращения ошибок и дорогостоящих ошибок, Среднеквадратичная ошибка (MSE) R-квадрат – это простая для понимания дробь. Однако я часто ценю немного больший уровень ошибок регрессии. Я ценю эти осязаемые факты и приемы из редких единиц зависимого аспекта. Когда я использую регрессионную модель для составления пророчеств, S сразу говорит мне, независимо от того, достаточно ли точна модель или нет. С другой стороны, R-квадрат не имеет единиц, и поэтому кажется неоднозначным, что S. Если мы знаем только R-квадрат, поэтому 76,1% без вопросов, мы не знаем, как часто в среднем это модель основана на ошибке. … Чтобы получить точные прогнозы, вам нужен размер R в квадрате, но вы не знаете, как именно он должен быть. Это потому, что очень сложно использовать R-квадрат для оценки правильности некоторых прогнозов. Чтобы продемонстрировать это, позвольте нам взглянуть на этот пример регрессии. Давайте представим, что наши мысли должны быть в пределах +/- 5% от всех вас, чтобы наблюдаемые значения всегда были полезны. Если экспертам известен только R-квадрат 76,1%, может ли кто-нибудь сказать, достаточно ли точна наша модель? Нет, вы не можете сказать этого с потрясающим R-квадратом. Однако вы можете использовать общую ошибку из-за регрессии. Чтобы наша модель обеспечивала требуемую точность, S должно быть меньше 2,5%, потому что 2,5 * 2 означает пару. Внезапно мы понимаем, что наша S (3.5), несомненно, слишком велика. Нужна ли нам более конкретная модель. Спасибо! Хотя мне очень нравится популярное “остающееся беспокойство”, конечно, вы можете посмотреть на точность совпадения в двух единицах одновременно. Это математический эквивалент того, что вы съели свой торт и взяли его! Если вы новичок в регрессии и вам нравится весь процесс, который я использую в своем блоге, ознакомьтесь с моей электронной книгой о Маркете!

Стандартная ошибка, которая на практике чаще всего связана с регрессией и R-квадратом
Пример регрессионной модели: ИМТ тела и процентное содержание жира
ПК работает медленно?

Я часто предпочитаю стандартную остаточную ошибку регрессии
Связано
О чем вам говорит существенная ошибка?
Популярная ошибка говорит вам, насколько реально полученный отбор пробы из этой колонии, несомненно, будет сравниваться со средним значением для текущей популяции. Если неохотная ошибка увеличивается, т. Е. H. Если средние значения могут быть больше, возрастает вероятность того, что большинство основных сообщаемых средств, а также истинное среднее значение общества будут неточными.
Как вы интерпретируете стандартизированную ошибку среднего?
Стандартная ошибка бренда – это возможность использования выборочной тактики с исходными единицами измерения, отклоняющимися от среднего значения. Опять же, более высокие области соответствуют более широкому распределению. С SEM, равным 3, мы знаем, где типичная разница между двумя значениями между выборкой и генеральной совокупностью на самом деле означает 3.
Tips For Correcting Standard Errors Indicating Regression
Conseils Pour Corriger Les Erreurs Standard Indiquant Une Régression
Wskazówki Dotyczące Korygowania Błędów Standardowych Wskazujących Na Regresję
Dicas Para Corrigir Erros Padrão Que Indicam Regressão
Sugerencias Para Corregir Errores Estándar Que Indican Regresión
Suggerimenti Per Correggere Gli Errori Standard Che Indicano Una Regressione
Tipps Zur Korrektur Von Standardfehlern, Die Auf Eine Regression Hinweisen
Tips Eftersom Korrigering Av Standardfel Som Indikerar Regression
회귀를 나타내는 표준 오류 수정을 위한 팁
Tips Voor Het Corrigeren Van Standaardfouten Die Regressie Aangeven
г.