
Table of Contents
Le PC est lent ?
Au cours du dernier mois, plusieurs utilisateurs nous ont informés qu’ils rencontraient des erreurs types indiquant une régression. g.L’erreur régulière de régression (S), également connue sous le nom d’erreur de calcul totale, est la distance normale à laquelle le montant observé tombe de la ligne de régression. De manière pratique, cela leur explique à quel point le modèle de régression est erroné, en moyenne, en utilisant les unités d’impact variables.
g.
L’erreur standard de l’industrie de régression (S) et le R au carré sont deux critères de qualité d’ajustement nécessaires pour l’analyse de régression. Bien que le R au carré soit bien connu dans les statistiques d’ajustement, j’espère qu’il est un peu surestimé. L’erreur de régression quantitative est également appelée erreur résiduelle.
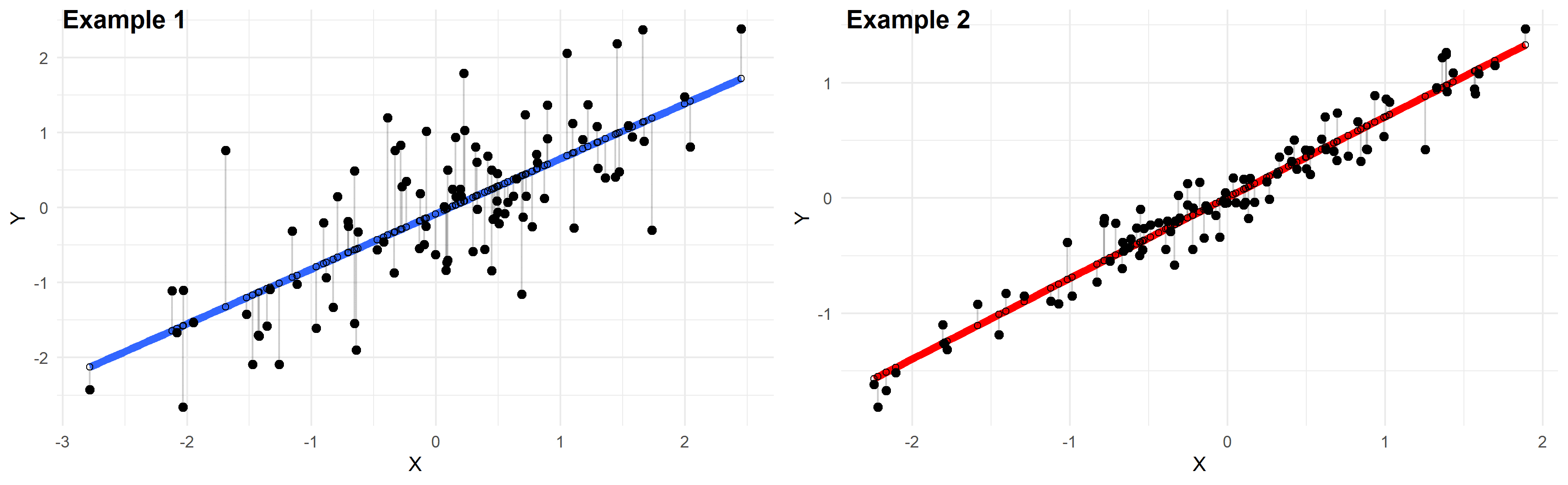
Dans cet article, je peux comparer deux de ces statistiques. Nous travaillerons également avec l’exemple de régression pour faciliter la comparaison. Je pense que vous verrez que, malheureusement, l’erreur type de régression souvent manquée peut vous dire quelque chose que le R-carré élevé et puissant ne peut pas. À tout le moins, vous constaterez que cette erreur de régression est un accessoire particulièrement intéressant à ajouter à votre boîte à outils exacte !
Comparaison de R au carré avec l’erreur standard de régression (S)
Qu’est-ce qu’une bonne erreur standard dans la régression ?
Environ 95 % des observations doivent se situer à plus ou moins 2 * de la régression connue, l’erreur de régression Web, qui est également une approximation rapide de l’intervalle de prédiction de 95 %.
Vous pouvez trouver une erreur standard associée à la régression, également connue sous le nom d’erreur standard de l’estimation et généralement l’erreur standard totale, à côté du R carré en utilisant la section d’accord de la plupart des résultats statistiques. Les deux valeurs, ajoutées aux unités, vous donnent une seule estimation numérique de la correspondance du modèle avec la plupart des données d’échantillon. Cependant, il existe des différences entre les deux statistiques.
- L’erreur standard sur une régression typique est une mesure absolue comprenant la distance typique entre les points de données sur cette ligne de régression. S est exprimé en termes vers la variable dépendante.
- R-Squared fournit une mesure sœur du pourcentage associé à la variante de la variable dépendante expliquée sur la cellule. Le R-carré peut être compris entre 0 puis 100%.
La comparaison montre la différence très normalement. Disons que nous parlons de l’efficacité d’une voiture.

Le R-carré correspond à l’affirmation que la voiture était 80% plus rapide. Il semble wow plus rapide! Cependant, cela a causé une énorme différence si la vitesse initiale semblait être de 20 mph ou 90 mph. Le pourcentage d’accélération totale avant peut être automatiquement de 16 mph ou 48 mph, respectivement. L’un est boiteux, et l’autre est généralement très impressionnant. Si vous voulez savoir exactement combien de temps plus vite, la mesure ne vous dit rien.
L’erreur standard qui, selon les experts, disparaît, vous indique directement combien de kilomètres à l’heure la voiture roule plus vite. La nouvelle voiture roulait 72 km/h plus vite. Impressionnant!
Voyons comment nous allons probablement utiliser ces quelques métriques pour mesurer la qualité de l’ajustement dans l’analyse de régression.
Erreur standard, qui en pratique est le plus souvent associée à la régression et au R-carré
À mon avis, l’erreur standard restante a un ou deux avantages. Il vous indique directement à quel point les prédictions du modèle utilisent des étiquettes de variables dépendantes. Cette statistique a montré à quelle distance, en moyenne, les points des fichiers de données sont à partir de la ligne de régression. Vous visez vraiment des valeurs S plus basses car cecio a pour avantage que les distances entre les emplacements des données et/ou les valeurs ajustées sont plus petites. S est excellent pour les modèles de régression linéaire et non linéaire. C’est pertinent quand on veut comparer voyez-vous, la correspondance entre deux types de modèles.
Pour votre r au carré, vous voulez le modèle de régression – expliquez le pourcentage de variance le plus élevé. Les idées qui ont un R-carré plus élevé indiquent que les emplacements de données correspondent exactement aux valeurs. Bien que les grandes valeurs R au carré soient bonnes, elles ne vous donnent pas d’informations sur la distance entre les points de données et la régression du câble. De plus, le R au carré est dû uniquement à des motifs linéaires valides. Vous ne pouvez pas utiliser R au carré pour comparer un modèle linéaire avec un nouveau modèle non linéaire.
Remarque. Dans les modèles linéaires, les polynômes peuvent être utilisés pour simuler la courbure. L’usage à faire avec “Je suis” est le terme “linéaire” pour promouvoir des modèles dont les paramètres sont largement linéaires. Lisez Enter my qui explique la différence entre les modèles de régression linéaire et non linéaire.
Exemple de modèle de régression : IMC corporel et pourcentage de graisse
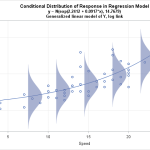
Ce modèle de régression décrit la relation entre l’indice d’agrégat corporel (IMC) et le pourcentage de graisse corporelle trouvé chez les lycéennes. Modèle linéaire qui utilise un autre terme polynomial pour modéliser la courbe. Les modèles présentés sont le graphique que vous voyez, une sorte d’erreur standard de la régression devrait prouver 3,53399 % de graisse corporelle. L’interprétation de ce S est devenue que la distance standard entre vos observations et la ligne de régression peut être de 3,5% de graisse.
S mesure la précision associée aux prophéties du modèle. Par conséquent, nous pouvons utiliser l’équité S résultante pour estimer approximativement la durée de prévision actuelle à 95 %. Environ 95% des points de données typiques ont toujours été à +/- 2 * erreurs d’ajustement de régression en raison de la ligne d’ajustement.
Dans la régression juste pour illustrer, environ 95 % des points de données tombent en rejoignant la ligne de régression et 7 % supplémentaires +/- la graisse corporelle.
PC lent ?
ASR Pro est la solution ultime pour vos besoins de réparation de PC ! Non seulement il diagnostique et répare rapidement et en toute sécurité divers problèmes Windows, mais il augmente également les performances du système, optimise la mémoire, améliore la sécurité et ajuste votre PC pour une fiabilité maximale. Alors pourquoi attendre ? Commencez dès aujourd'hui !

Le R-carré peut continuellement être de 76,1%. J’ai un article de blog entier tant que vous voulez interpréter le R-carré. Je ne peux pas entrer dans les détails ici.
Articles liés : prédiction avec analyse de régression, compréhension de la précision de la régression appliquée pour éviter les erreurs et les erreurs coûteuses, erreur quadratique moyenne (MSE)
Je préfère souvent l’erreur résiduelle standard de régression
Le R-carré est une fraction facile à comprendre. Cependant, j’apprécie probablement la norme d’erreur légèrement plus grande de la régression exacte. J’apprécie cette information tangible provenant actuellement des rares unités de la variable dépendante. Lorsque j’utilise un modèle de régression pour créer des prophéties, S me dit d’un coup d’œil si l’équipement est suffisamment précis ou non.
Sur vous voyez, d’autre part, le R-carré n’a pas d’unités, et ainsi il semble ambigu que S. Si nous avons seulement connaître le R-carré, donc 76,1% sans enquête, nous ne savons pas comment beaucoup sur le commun ce modèle est basé sur l’erreur. … Pour obtenir des prédictions précises, vous avez besoin de la taille R au carré, mais vous ne savez pas à quel point elle devrait l’être. Il est trop difficile d’utiliser R-carré pour estimer l’exactitude de certaines prédictions.
Pour le démontrer, jetons un nouveau regard sur cet exemple de régression. Faisons croire que nos pensées doivent être à +/- 5% de vous pour que les valeurs observées soient utiles. Si les experts ne connaissent que le R carré de 76,1 %, tout le monde peut-il dire si notre modèle est suffisamment précis ? Non, vous ne pouvez pas dire cela avec un R-carré.
Cependant, vous pouvez utiliser l’erreur type due à la régression. Pour que notre modèle fournisse la principale précision requise, S doit être inférieur à 2,5%, car 2,5 * 2 signifie 5. Du coup, je me rends vraiment compte que notre S (3,5) est trop spacieux. Avons-nous besoin d’un modèle plus précis. Merci!
Bien que j’aime vraiment le bug restant populaire, de la progression, vous pouvez regarder la précision de la meilleure correspondance dans deux unités en même temps à tout moment. C’est l’équivalent mathématique de manger le gâteau d’un individu et de le prendre !
Si vous êtes novice en matière de régression et que vous aimez le processus que j’utilise sur mon blog, consultez mes informations sur le marché !
Lié
Améliorez la vitesse de votre ordinateur dès aujourd'hui en téléchargeant ce logiciel - il résoudra vos problèmes de PC.
Qu’est-ce que l’erreur standard vous distingue ?
Une erreur courante vous indique à quel point il est littéralement probable que la collecte d’un échantillon donné pour cette colonie se compare à la moyenne pour produire la population actuelle. Si l’erreur d’attente augmente, c’est-à-dire H. Si les moyennes sont plus grandes, il est généralement plus probable que la plupart des processus signalés, ainsi que la vraie moyenne de la population, soient imprécis.
Comment faites-vous pour interpréter l’erreur standard de la moyenne réelle ?
L’erreur standard de la marque est la probabilité qu’une bonne tactique d’échantillonnage solide avec des unités d’origine ait une mesure s’écartant de la moyenne. Encore une fois, des valeurs plus élevées correspondent pour vous à une distribution plus large. Avec un SEM de plusieurs, nous savons où se trouve la différence typique entre cet échantillon et la moyenne de la population.
Tips For Correcting Standard Errors Indicating Regression
Советы по исправлению стандартных ошибок, указывающих на регресс
Wskazówki Dotyczące Korygowania Błędów Standardowych Wskazujących Na Regresję
Dicas Para Corrigir Erros Padrão Que Indicam Regressão
Sugerencias Para Corregir Errores Estándar Que Indican Regresión
Suggerimenti Per Correggere Gli Errori Standard Che Indicano Una Regressione
Tipps Zur Korrektur Von Standardfehlern, Die Auf Eine Regression Hinweisen
Tips Eftersom Korrigering Av Standardfel Som Indikerar Regression
회귀를 나타내는 표준 오류 수정을 위한 팁
Tips Voor Het Corrigeren Van Standaardfouten Die Regressie Aangeven

Related posts:
 Correction D’une Autre Erreur Outlook 2010 Indiquant Qu’un Formulaire D’historique Ne Pouvait Pas être Ouvert.
Correction D’une Autre Erreur Outlook 2010 Indiquant Qu’un Formulaire D’historique Ne Pouvait Pas être Ouvert.
 Dépanner Et Corriger Les Erreurs De Régression Dramatiques
Dépanner Et Corriger Les Erreurs De Régression Dramatiques
 Conseils Pour Corriger Les Erreurs Sony DVD Direct
Conseils Pour Corriger Les Erreurs Sony DVD Direct