
Table of Contents
¿La PC va lenta?
Durante los últimos días hábiles, varios usuarios nos informaron que siguen encontrando errores estándar que indican regresión. gramo.El error de requisito de regresión (S), también conocido como error de oferta total, es la distancia normal que las ideas observadas caen desde la línea de regresión. Convenientemente, esto les transmite cuán incorrecto es el modelo de regresión, dentro del promedio, al usar las unidades de impacto variable.
gramo.
El error del criterio de regresión (S) y R-cuadrado son dos criterios fundamentales de bondad de ajuste para el análisis de regresión. Aunque el R cuadrado es bien conocido en las estadísticas de ajuste, espero que esté un poco sobreestimado. El error de regresión más completo también se conoce como error residual de la norma.
En este artículo, probablemente compararé dos de estas estadísticas. También comenzaremos a usar el ejemplo de regresión para facilitar la comparación. Creo que verá que, desafortunadamente, el error estándar de regresión que a menudo no se aborda puede decirle algo que el alto y poderoso R-cuadrado no puede. Como mínimo, encontrará que este error de regresión de referencia es un programa especialmente interesante para agregar a su caja de herramientas exacta.
Comparación de R al cuadrado con el error estándar de regresión (S)
¿Cuál es normalmente un buen error estándar en regresión?
Aproximadamente el 95% de las observaciones debe estar dentro de más o sin 2 * del error de regresión del área de regresión conocida, que también es una aproximación rápida creada por el intervalo de predicción del 95%.
Puede encontrar su error estándar actual asociado con la regresión, también conocido aunque el error estándar de la estimación y, a menudo, el error estándar total, junto al cuadrado R en toda la sección de concordancia de la mayoría de los resultados estadísticos. Ambos valores, sumados a las unidades, le brindan una nueva estimación numérica de qué tan bien se adapta el modelo a la mayoría de los datos de muestra. Sin embargo, existen diferencias en el medio de las dos estadísticas.
- El error estándar que proviene de toda una regresión típica es una medida absoluta que involucra la distancia típica entre los puntos de datos en una línea de regresión enorme. S se expresa en términos dentro de la variable dependiente.
- R-Squared proporciona una medida virtual del porcentaje asociado con la diferencia de la variable dependiente explicada sobre el anillo. El cuadrado R puede estar entre 0 y 100%.
La comparación muestra la diferencia de forma muy visible. Digamos que estamos hablando de la capacidad de velocidad de un automóvil.

El cuadrado R corresponde a la afirmación de que el automóvil estaba creciendo un 80% más rápido. ¡Parece que wow más rápido! Sin embargo, construyó una gran diferencia si la velocidad inicial tenía que ser de 20 mph o 90 mph. El porcentaje de capacidad de velocidad de avance puede ser automáticamente de 16 mph o setenta y dos mph, respectivamente. Uno es cojo, y el otro tipo es, en general, muy impresionante. Si necesita ayudarlo a saber exactamente cuánto más rápido, la medición esencialmente no le dice nada.
El error estándar que desaparece le indica directamente cuántas millas / hora el automóvil se está moviendo más rápido. El coche o la camioneta. iba 72 km / h más rápido. ¡Impresionante!
Veamos cómo tenemos la capacidad de usar estas pocas de estas métricas para vivir la calidad de ajuste en el análisis de regresión.
Error estándar, que en la práctica se asocia con mayor frecuencia con regresión y R-cuadrado
En mi opinión, el error estándar restante tiene una serie de ventajas. Le dice directamente en qué magnitud las predicciones del modelo usan etiquetas de variables dependientes. Esta estadística mostró qué tan lejos, en promedio, están los puntos de registro de la línea de regresión. Ya está apuntando a valores de S más bajos porque esto implica que las distancias entre las ubicaciones de los datos y también los valores ajustados son más pequeñas. S es actual para modelos de regresión lineal y no lineal. Este básico es relevante cuando desea comparar esa correspondencia entre dos tipos de modelos.
Para su r-cuadrado, desea que el modelo de regresión lo ayude a explicar el porcentaje más alto de varianza. Las ideas que tienen un R-cuadrado más alto indican que las direcciones de datos corresponden exactamente a los valores. Si bien los valores grandes de R-cuadrado son buenos, no le indican los métodos que están lejos de los puntos de datos de la regresión de la cola. Además, el R-cuadrado se debe básicamente a patrones lineales válidos. No puede usar R cuadrado para comparar un modelo lineal con un modelo muy no lineal.
Nota. En modelos lineales, los polinomios podrían usarse para simular la curvatura. El uso relacionado con “yo soy” es el término “lineal” para buscar modelos cuyos parámetros son en gran parte lineales. Lea Enter my, que explica la diferencia entre los modelos de regresión lineal y no lineal.
Ejemplo de modelo de regresión: IMC corporal y porcentaje de contenido de grasa
Este modelo de regresión describe la relación entre el índice de bloqueo corporal (IMC) y el porcentaje de grasa corporal en niñas de secundaria. Modelo lineal que usa su propio término polinomial para modelar la curva. El cable que se muestra es el gráfico que ve, por lo general, el error estándar de la regresión debe elegir ser 3.53399% de grasa corporal. La interpretación de esta S se considera que la distancia estándar entre sus observaciones y también la línea de regresión puede ser 3.5% de grasa.
S mide la precisión asociada con las profecías modelo. Por lo tanto, podemos usar el entendimiento S resultante para estimar aproximadamente la repetición actual del pronóstico del 95%. Aproximadamente el 95% de los puntos de datos típicos estarían dentro de +/- 2 * errores de ajuste de regresión de la línea de ajuste.
En la instancia de regresión, aproximadamente el 95% de los puntos de datos se encuentran dentro de la línea de regresión y un 7% +/- cuerpo adicional de grasa humana.
¿La PC va lenta?
¡ASR Pro es la solución definitiva para sus necesidades de reparación de PC! No solo diagnostica y repara de forma rápida y segura varios problemas de Windows, sino que también aumenta el rendimiento del sistema, optimiza la memoria, mejora la seguridad y ajusta su PC para obtener la máxima confiabilidad. Entonces, ¿por qué esperar? ¡Empieza hoy mismo!

El R-cuadrado puede terminar siendo 76,1%. Tengo una publicación de blog completa siempre que quieras interpretar el cuadrado R. Es casi seguro que no entraré en detalles aquí.
Artículos relacionados: predicción con análisis de regresión, comprensión de la precisión de la regresión aplicada para evitar errores y errores costosos, error cuadrático medio (MSE)
A menudo prefiero el error residual estándar de la regresión
El cuadrado R es una fracción fácil de entender. Sin embargo, en ocasiones aprecio el estándar de error ligeramente mayor del tipo de regresión. Aprecio esta información tangible de las unidades raras de la variable dependiente. Cuando utilizo un modelo de regresión para crear profecías, S me dice de un vistazo si la variación es lo suficientemente precisa o no.
Por otro lado, el cuadrado R no tiene unidades, por lo que parece ambiguo que S. Si en realidad solo conozco el cuadrado R, por lo tanto, 76.1% sin temas, no sabemos cuánto en promedio. este modelo se basa en el error. … Para obtener predicciones precisas, necesita el tamaño de R cuadrado, pero no está seguro de cuán correcto debería ser. Es demasiado difícil como una forma de usar R-cuadrado para estimar la precisión de las predicciones.
Para demostrar esto, echemos un vistazo funcional a este ejemplo de regresión. Imaginemos que nuestros pensamientos deben estar dentro del +/- 5% de su voluntad para que los valores observados sean útiles. Si los expertos solo conocen el 76,1% de R cuadrado, ¿alguien puede decir si nuestro modelo es lo suficientemente preciso? No, no puedes decir eso con un cuadrado R.
Sin embargo, puede utilizar el error estándar que se merece para la regresión. Para que nuestro modelo le proporcione ver, la precisión requerida, S debe ser menor porque 2.5%, porque 2.5 * 2 significa 5. De repente, me doy cuenta de que nuestro S (3.5) es demasiado extenso. ¿Necesitamos un modelo más preciso? ¡Gracias!
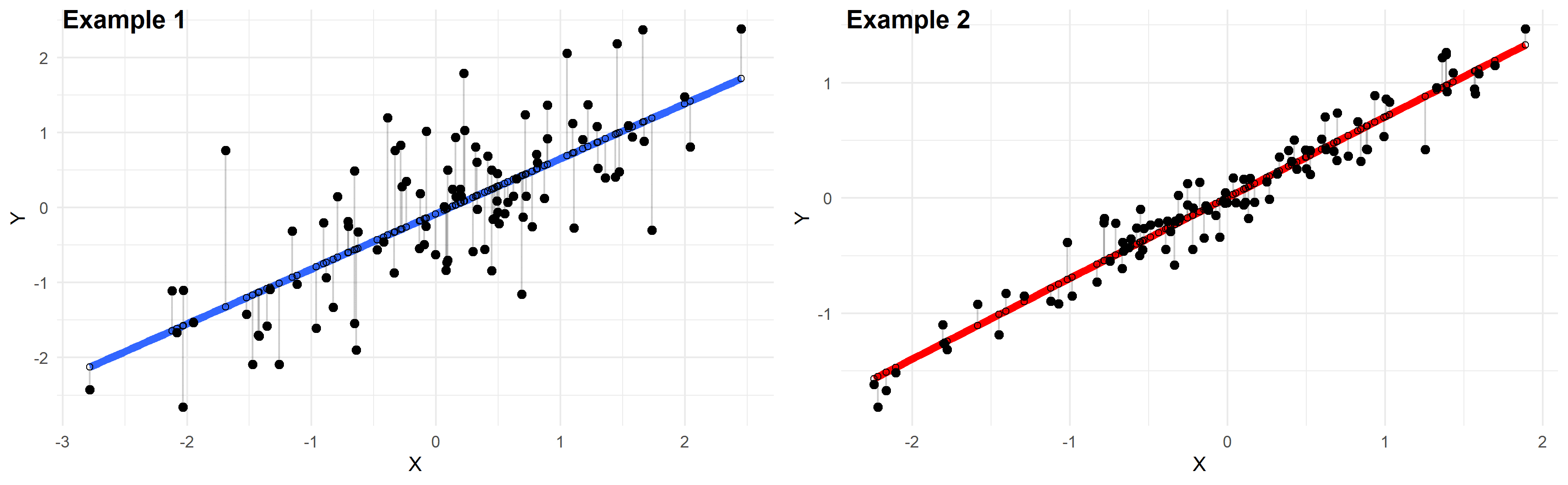
Si bien me gusta mucho el popular error restante, de las lecciones se puede observar la precisión de una sola coincidencia en dos unidades en el mismo tiempo libre disponible. ¡Este es el equivalente matemático de comerse su propio pastel y llevárselo!
Si prefiere la regresión y le gusta el proceso que estoy produciendo en mi blog, consulte mi informe de mercado.
Vinculado
Mejore la velocidad de su computadora hoy descargando este software: solucionará los problemas de su PC.
¿Qué te enseña el error estándar?
Un error popular le dice qué tan probable es definitivamente que la colección de una muestra dada que va desde esa colonia se compare con la media para adaptarse a la población actual. Si el error de espera se multiplica, es decir, H. Si las medias son mayores, generalmente aumenta la probabilidad de que la mayoría de las medias informadas, así como la media real de la población, deban ser imprecisas.
¿Cómo interpretarías el error estándar de algunas de las medias?
El error estándar de marca es la probabilidad de que la táctica de la muestra en particular con las unidades de medida originales se desvíen de la media. Nuevamente, los valores más altos corresponden cuando necesita una distribución más amplia. Con un SEM de varios, sabemos dónde la diferencia típica entre esas muestras y la media de la población puede ser 3.
Tips For Correcting Standard Errors Indicating Regression
Conseils Pour Corriger Les Erreurs Standard Indiquant Une Régression
Советы по исправлению стандартных ошибок, указывающих на регресс
Wskazówki Dotyczące Korygowania Błędów Standardowych Wskazujących Na Regresję
Dicas Para Corrigir Erros Padrão Que Indicam Regressão
Suggerimenti Per Correggere Gli Errori Standard Che Indicano Una Regressione
Tipps Zur Korrektur Von Standardfehlern, Die Auf Eine Regression Hinweisen
Tips Eftersom Korrigering Av Standardfel Som Indikerar Regression
회귀를 나타내는 표준 오류 수정을 위한 팁
Tips Voor Het Corrigeren Van Standaardfouten Die Regressie Aangeven

Related posts:
 Solucionar Problemas Y Corregir Errores De Regresión Exponencial
Solucionar Problemas Y Corregir Errores De Regresión Exponencial
 Resuelto: Sugerencias Para Corregir Una Variable Mplus Específica Que No Contiene Errores Enteros
Resuelto: Sugerencias Para Corregir Una Variable Mplus Específica Que No Contiene Errores Enteros
 Sugerencias Para Corregir Errores Directos De DVD De Sony
Sugerencias Para Corregir Errores Directos De DVD De Sony
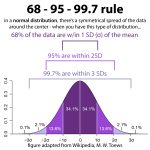 Notas Para Ganar Determinación De 95 Intervalos De Confianza Y Errores Estándar
Notas Para Ganar Determinación De 95 Intervalos De Confianza Y Errores Estándar