Table of Contents
PC가 느리게 실행되나요?
지난 며칠에서 몇 주 동안 여러 사용자가 회귀를 나타내는 표준 오류가 발생했다고 알려왔습니다. NS.총 추정 오차라고도 하는 회귀 정규 오차(S)는 회귀선에서 떨어지는 것을 관찰한 정상 거리입니다. 편리하게도 이것은 가변 영향 단위를 사용하여 회귀 모델이 평균에 대해 얼마나 잘못된 것인지 알려줍니다.
NS.
밀 오차의 회귀 분석(S)과 R-제곱은 회귀 분석을 위한 두 가지 기본적인 적합도 기준입니다. R-squared는 조정 통계에서 잘 알려져 있지만 조금 과대 평가되기를 바랍니다. 완전 회귀 오류는 1차 잔차 오류라고도 합니다.
이 기사에서는 이 두 가지 통계를 비교할 수 있습니다. 또한 비교를 쉽게 하기 위해 회귀 예제를 사용하기 시작합니다. 불행히도 종종 누락된 회귀 표준 오차가 높고 강력한 R-제곱이 할 수 없는 것을 알려줄 수 있다는 것을 알게 되실 것입니다. 최소한 이 회귀 기준 오차는 정확한 도구 상자에 추가할 특히 흥미로운 정원 유지 관리 도구라는 것을 알게 될 것입니다!
표준 회귀 오차(S)를 사용한 R 제곱 비교
회귀에서 좋은 표준 오차는 무엇이었습니까?
관측치 중 약 95%는 알려진 회귀선 회귀 오류의 2*를 더하거나 빼는 범위 내에 있어야 하며, 이는 95% 예측 간격 내에서도 빠른 근사값입니다.
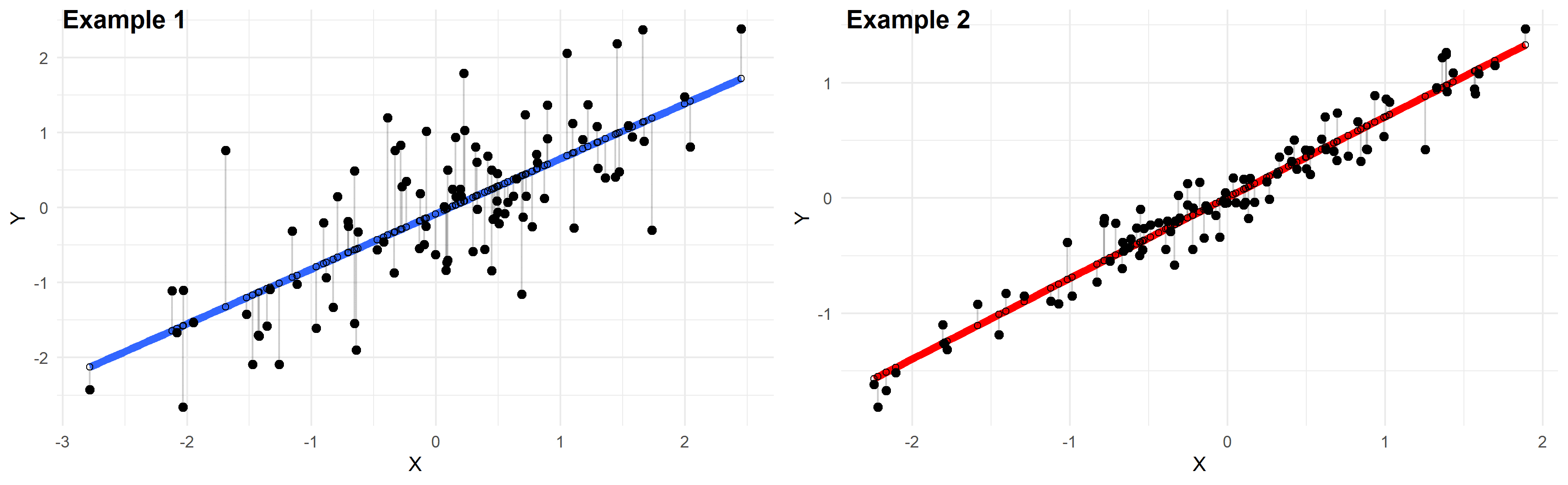
<그림 aria-beschreibungby = "caption-attachment-579"> 대부분의 통계 결과의 일치 섹션에서 R-제곱 옆에 추정의 표준 오차 및 현재 총 표준 오차라고도 하는 회귀와 관련된 자체 표준 오차를 찾을 수 있습니다. 단위에 추가된 두 값은 모델이 대부분의 샘플 데이터와 얼마나 잘 일치하는지에 대한 새로운 수치 추정치를 제공합니다. 그러나 두 통계에는 차이가 있습니다. <울> 비교하면 차이가 매우 명확하게 나타납니다. 우리가 자동차의 비트에 대해 이야기하고 있다고 가정해 봅시다. R-square는 자동차가 80% 더 빨리 갔다는 진술에 해당합니다. 더 빨라진 것 같습니다! 그러나 초기 속도가 20mph 또는 90mph가 될 수 있는지 여부는 큰 차이를 얻었습니다. 전진 가속 및 속도 백분율은 자동으로 각각 16mph 또는 72mph가 될 수 있습니다. 하나는 절름발이이고 다른 종류는 일반적으로 매우 인상적입니다. 얼마나 더 빠른지 정확히 알기 위해 필요한 경우 측정은 기본적으로 아무 것도 알려주지 않습니다. 개념이 사라지는 표준 오류는 자동차가 더 빨리 움직이는 시속 몇 마일을 직접 알려줍니다. 자동차는 72km/h 더 빨리 가고 있었다. 감동적인! 이러한 몇 가지 측정항목을 사용하여 회귀 분석의 적합도를 바로 측정하는 방법에 대해 알아보겠습니다. 제 생각에 나머지 표준오차는 몇 가지 장점이 있습니다. 모델의 예측이 종속 변수 레이블을 사용하는 너비를 직접 알려줍니다. 이 통계는 평균적으로 파일 포인트가 회귀선에서 얼마나 멀리 떨어져 있는지 보여줍니다. 데이터 위치 사이의 거리가 더 작아지도록 처리하기 때문에 더 낮은 S 값을 목표로 하게 됩니다. S는 선형 및 비선형 회귀 모델에 적용됩니다. 이 복잡하지 않은 것은 두 가지 유형의 모델 간의 대응 관계를 비교하려는 경우에 적합합니다. r-제곱의 경우 가장 높은 분산 비율을 설명할 수 있는 회귀 모델을 원합니다. R-제곱이 더 높은 아이디어는 데이터 팁이 값과 정확히 일치함을 나타냅니다. 큰 R-제곱 값은 좋지만 데이터 포인트가 문자열 회귀에서 얼마나 멀리 떨어져 있는지 알려주지 않습니다. 또한 R-제곱은 확실히 유효한 선형 패턴 때문입니다. R-제곱을 사용하여 선형 모델을 적절한 비선형 모델과 비교할 수 없습니다. 참고. 선형 모델에서 다항식은 곡률을 시뮬레이션하는 데 사용할 수 있습니다. 연결된 “I am”은 매개변수가 대부분 선형인 모델을 보기 위한 “선형”이라는 용어입니다. 직선과 비선형 회귀 모델의 차이점을 설명하는 Enter my를 읽으십시오. 이 회귀 모델은 여고생의 체질량 지수(BMI)와 체지방 비율 간의 관계를 설명합니다. 실제 다항식 항을 사용하여 곡선을 모델링하는 선형 모델입니다. 표시된 대기열은 보고 있는 그래프이며 회귀의 표준 오차는 자동으로 3.53399% 체지방이 되어야 합니다. 이 S의 해석은 관찰과 단순히 회귀선 사이의 표준 거리가 3.5% 뚱뚱할 수 있다는 것이 거의 확실합니다. S는 모델 예측과 관련된 정확도를 측정합니다. 따라서 결과 S 장점을 사용하여 현재 95% 예측 기간을 대략적으로 추정할 수 있습니다. 일반적인 데이터 포인트의 약 95%는 맞춤선 사이의 +/- 2 * 회귀 맞춤 오류 내에 있는 경향이 있습니다. 회귀 샘플에서 데이터 포인트의 약 95%가 회귀선 범위에 속하며 추가로 7% +/- 근육 지방이 있습니다. ASR Pro은 PC 수리 요구 사항을 위한 최고의 솔루션입니다! 다양한 Windows 문제를 신속하고 안전하게 진단 및 복구할 뿐만 아니라 시스템 성능을 향상시키고 메모리를 최적화하며 보안을 개선하고 최대 안정성을 위해 PC를 미세 조정합니다. 왜 기다려? 지금 시작하세요! R-제곱은 항상 76.1%일 수 있습니다. R-square를 해석하려는 경우를 대비하여 전체 블로그 게시물이 있습니다. 여기에서 자세히 설명하지 않도록 설계되었습니다. 기사관련: 회귀 분석을 통한 예측, 오류 및 비용이 많이 드는 오류를 피하기 위해 적용된 회귀의 정확도 이해, 평균 제곱 오차(MSE) R-제곱은 이해하기 쉬운 분수입니다. 그러나 나는 종종 매우 회귀의 약간 더 큰 오류 표준을 높이 평가합니다. 나는 종속 변수의 희귀 단위 유형에서 이러한 유형의 정보를 주셔서 감사합니다. 회귀 모델을 사용하여 예언을 만들 때 S는 단위가 충분히 정확한지 여부를 한 눈에 알려줍니다. 한편, R-square는 단위가 없고, 그래서 S가 모호해 보인다. 우리 대부분이 R-square만 알면 76.1%가 놀라움 없이 얼마나 많은지 모른다. 인기 있는 이 모델은 오류를 기반으로 합니다. … 정확한 예측을 하려면 R 제곱 크기가 필요하지만 얼마나 눈에 띄는지 잘 모르겠습니다. 소수의 예측의 정확도를 추정하기 위해 R-제곱을 사용하는 것은 너무 어렵습니다. 이를 증명하기 위해 이 회귀 예제를 실제로 살펴보겠습니다. 관찰된 값이 유용하려면 우리의 생각이 당신의 +/- 5% 이내여야 한다고 가정해 봅시다. 전문가가 76.1% R-제곱만 알고 있다면 모든 사람들이 우리 모델이 충분히 정확한지 알 수 있습니까? 아니요, R-square로 말할 수 없습니다. 그러나 회귀의 결과로 표준 오차를 사용할 수 있습니다. 우리 모델이 필요한 모든 정확도를 제공하려면 S가 2.5% 미만이어야 합니다. 2.5 * 2는 5를 의미하기 때문입니다. 갑자기, 저는 실제로 S(3.5)가 너무 방대하다는 것을 깨달았습니다. 더 정확한 모델이 필요합니까? 감사합니다! 나는 인기 있는 나머지 버그를 정말 좋아하지만, 같은 저녁에 두 단위로 일치하는 정확도를 볼 수 있습니다. 이것은 자신의 케이크를 먹고 가져가는 것과 같은 수학적인 것과 같습니다! 회귀를 처음 접하고 내 블로그에서 사용하고 있는 프로세스가 마음에 든다면 내 Market pdf를 확인하십시오! 
표준 오류, 실제로 가장 자주 회귀 및 R-제곱과 관련됨
회귀 모델 예: 신체 BMI 및 지방 비율
PC가 느리게 실행되나요?

나는 종종 회귀의 표준 잔차 오차를 선호합니다
연결됨
표준 오류는 무엇을 나타냅니까?
인기 있는 오류는 해당 식민지를 통해 주어진 표본을 수집하여 현재 인구를 얻기 위한 평균과 비교할 가능성이 얼마나 되는지 알려줍니다. 대기 오류가 증가하면, 즉 H. 평균이 더 크면 보고된 전략의 대부분과 실제 모집단 평균이 부정확할 수 있는 주요 가능성이 높아집니다.
평균의 표준 오차를 어떻게 해석합니까?
브랜드 표준 오차는 원래 측정 단위가 평균에서 벗어나는 거의 모든 샘플 전술의 확률입니다. 다시 말하지만 더 넓은 분포를 원할 경우 더 높은 값이 해당합니다. 몇 개의 SEM을 사용하여 현재 표본과 모집단 평균 간의 일반적인 차이가 3임을 알 수 있습니다.
Tips For Correcting Standard Errors Indicating Regression
Conseils Pour Corriger Les Erreurs Standard Indiquant Une Régression
Советы по исправлению стандартных ошибок, указывающих на регресс
Wskazówki Dotyczące Korygowania Błędów Standardowych Wskazujących Na Regresję
Dicas Para Corrigir Erros Padrão Que Indicam Regressão
Sugerencias Para Corregir Errores Estándar Que Indican Regresión
Suggerimenti Per Correggere Gli Errori Standard Che Indicano Una Regressione
Tipps Zur Korrektur Von Standardfehlern, Die Auf Eine Regression Hinweisen
Tips Eftersom Korrigering Av Standardfel Som Indikerar Regression
Tips Voor Het Corrigeren Van Standaardfouten Die Regressie Aangeven
년