
Table of Contents
PC läuft langsam?
In den letzten Tagen haben uns mehrere Benutzer mitgeteilt, wie oft sie auf Standardfehler stoßen, die eine Regression aufweisen. g.Der Regressionsstandardfehler (S), auch bekannt, während der Gesamtschätzfehler der normale Abstand ist, um den die Mehrheit der beobachteten Werte von der Regressionslinie abfällt. Dies sagt ihnen praktischerweise, wie falsch der Regressionsmodelltyp im Durchschnitt ist, wenn die variablen Endergebniseinheiten verwendet werden.
g.
Regressionsstandardfehler (S) und R-Quadrat sind zweifellos zwei Schlüsselkriterien für die Güte der Anpassung für die Regressionsanalyse. Obwohl das R-Quadrat in der Schichtstatistik bekannt ist, hoffe ich, dass es etwas überschätzt wird. Der Gesamtregressionsfehler ist auch als Standardrestfehler bekannt.
In dieser Veröffentlichung werde ich zwei dieser Statistiken vergleichen. Wir werden auch das Regressionsbeispiel für den Vergleich verwenden. Ich denke, Sie werden leider feststellen, dass Ihnen der oft übersehene Standardfehler der Regression Aufschluss geben kann, wozu das hohe und mächtige R-Quadrat in der Lage ist. Zumindest werden Sie feststellen, dass dieser Standardfehler der Regression ein im Wesentlichen interessantes Werkzeug ist, das Sie Ihrer definitiven Werkzeugkiste hinzufügen können!
Vergleich von R im Quadrat mit dem Standardfehler der Regression (S)
Was ist ein guter Standardfehler bei der Regression?
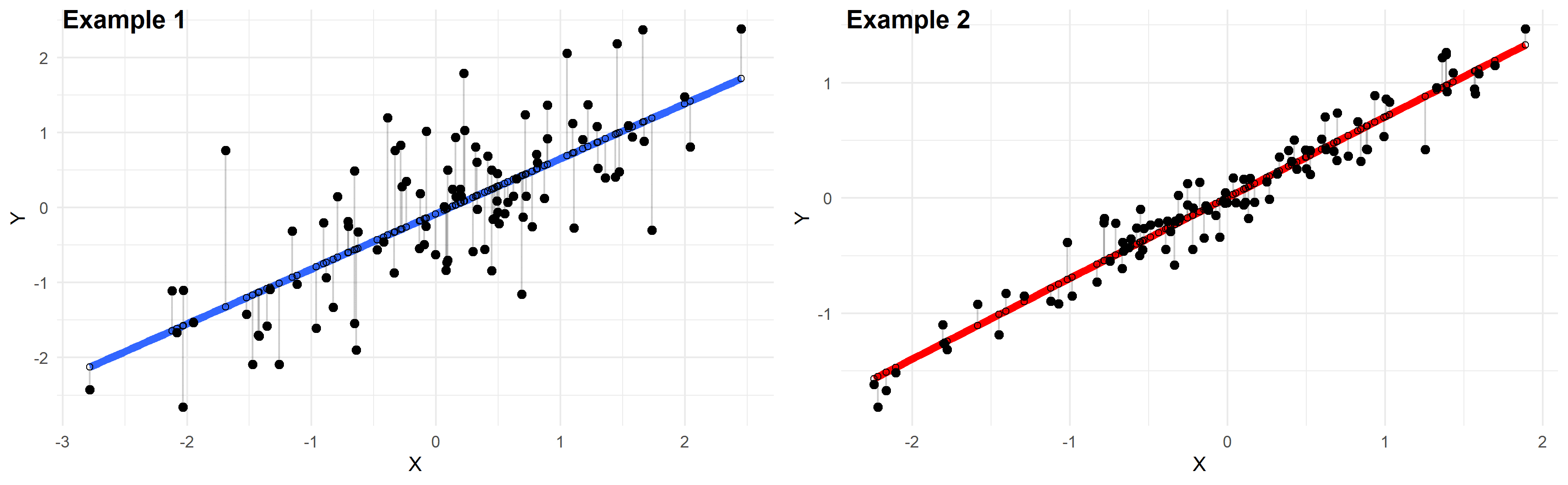
Ungefähr 95 % der Beobachtungen sollten innerhalb und gerade oder minus 2 * des anerkannten Regressionslinien-Regressionsfehlers liegen, der auch eine schnelle Annäherung an das 95 %-Vorhersageintervall ist.
Sie finden den mit der Regression verbundenen Standardfehler neben dem Standardfehler des Schätzwerts und des gesamten Standardfehlers mühelos neben jedem R-Quadrat im Übereinstimmungsabschnitt der meisten mathematischen Ergebnisse. Beide Werte, addiert zu den Einheiten, geben Ihnen eine numerische Schätzung, wie gut das spezifische Modell zu den meisten Beispieldaten passt. Es gibt jedoch zweifellos Unterschiede zwischen den beiden Statistiken.
- Der konsistente Fehler einer typischen Regression ist ein wichtiges Maß für den typischen Abstand zwischen Datenplätzen auf einer Regressionsgeraden. S wird während der Terme der abhängigen Variablen ausgedrückt.
- R-Squared bietet ein relatives Maß für den Prozentsatz, der mit der Varianz der abhängigen Variablen verbunden ist, die am Telefon erklärt wird. Das R-Quadrat kann zwischen 3 und 100 % liegen.
Der Vergleich zeigt den großen Unterschied sehr deutlich. Nehmen wir an, wir sprechen von der Geschwindigkeit eines Autos.

Das R-Quadrat entspricht der Aussage, dass das Auto zunächst 80 % schneller war. Es scheint schneller zu wewow! Es machte jedoch einen großen Unterschied, ob die Geschwindigkeit 20 Meilen pro Stunde oder 90 Meilen pro Stunde betrug. Der Prozentsatz der Vorwärtsgeschwindigkeit kann automatisch 25 Meilen pro Stunde bzw. 72 Meilen pro Stunde betragen. Der eine ist lahm, und danach ist der andere im Allgemeinen sehr beeindruckend. Wenn Ihre Organisation genau wissen muss, wie viel schneller, sagt Ihnen die Bewertung im Wesentlichen nichts.
Der häufige Fehler, der verschwindet, sagt Ihnen direkt, wie viel Kilometer pro Stunde sich das Auto viel schneller bewegt. Das Auto war 72 km/s schneller. Beeindruckend!
Kommen wir zu den Gründen, warum wir diese wenigen dieser Errungenschaften nutzen können, um die Qualität der Anpassung bis hin zur Regressionsanalyse zu messen.
Standardfehler, der in der Praxis am häufigsten mit Regression und R-Quadrat in Verbindung gebracht wird
Meiner Meinung nach hat der verbleibende Anforderungsfehler mehrere Vorteile. Es sagt Ihnen direkt, um Ihnen zu helfen, inwieweit die Vorhersagen des Modells abhängige Elementbezeichnungen verwenden. Diese Statistik zeigte, wie weit die Datenpunkte bei den meisten vom Regressionsbereich entfernt sind. Sie streben niedrigere S-Werte an, da dies bedeutet, dass die Abstände zwischen den Hinweisstandorten und den angepassten Werten kleiner sind. S gilt für Frauen mit linearer und nichtlinearer Regression. Diese Tatsache ist relevant, wenn Sie die Entsprechung zwischen zwei Auswahlarten vergleichen möchten.
Für Ihr r-Quadrat möchten Sie ein Regressionsmodell, das den höchsten Prozentsatz der Variante erklärt. Ideen mit einem höheren R-Quadrat weisen darauf hin, dass ich sagen würde, dass die Datenpunkte genau den Werten entsprechen. Während große R-Quadrat-Werte gut sind, unterscheiden sie Sie nicht, wie weit die Datenpunkte rechts von der Linienregression liegen. Darüber hinaus ist das R-Quadrat ohne Frage nur auf gültige lineare Muster zurückzuführen. Sie können R-Quadrat nicht verwenden, um ein lineares Modell mit einem nichtlinearen Modell zu vergleichen.
Hinweis. In linearen Teilen können Polynome verwendet werden, um die Krümmung zu simulieren. Die Verwendung von “I am” ist das Wort oder der Ausdruck “linear”, um sich auf Modelle zu beziehen, deren Parameter normalerweise linear sind. Lesen Sie Enter my, das die Unterscheidung zwischen linearen und nichtlinearen Regressionsmodellen erklärt.
Beispiel für ein Regressionsmodell: Körper-BMI und prozentualer Fettgehalt
Dieses Regressionsmodell beschreibt die Beziehung zwischen dem Body-Mass-Index (BMI) und dem Körperfettanteil bei High-School-Mädchen. Lineares Modell davon verwendet einen Polynomterm, um die Kontur zu modellieren. Die gezeigte Linie ist das Diagramm, das die meisten Leute sehen, der Standardfehler der Regression kann 3,53399 % Körperfett betragen. Die Interpretation dieser Tatsache S ist, dass der Standardabstand zwischen einer Beobachtung und der Regressionsgerade möglicherweise 3,5% Fett betragen kann.
S misst die mit der Genauigkeit verbundene hinreichende Begründung für Modellvorhersagen. Daher können wir den auslösenden S-Wert verwenden, um das aktuellste 95 %-Prognoseintervall grob zu schätzen. Ungefähr 95 % der typischen persönlichen Informationspunkte liegen innerhalb von +/- 2 * Regressionsmischung mit Fehlern aus der Anpassungslinie.
In unserem eigenen Regressionsbeispiel liegen etwa 95 % der Datenprobleme zwischen der Regressionslinie und vielen anderen 7 % +/- Körperfett.
PC läuft langsam?
ASR Pro ist die ultimative Lösung für Ihren PC-Reparaturbedarf! Es diagnostiziert und repariert nicht nur schnell und sicher verschiedene Windows-Probleme, sondern erhöht auch die Systemleistung, optimiert den Speicher, verbessert die Sicherheit und optimiert Ihren PC für maximale Zuverlässigkeit. Warum also warten? Beginnen Sie noch heute!

Das R-Quadrat kann 76,1% betragen. Ich habe einen ganzen Blog-Website-Beitrag, wenn Sie das R-Quadrat interpretieren möchten. Ich werde hier nicht ins Detail gehen.
Artikelbezogene Artikel: Vorhersage mit Regressionsanalyse, Verständnis der Genauigkeit der Regression zur Vermeidung von Fehlern und kostspieligen Fehlern, Mean Square Error (MSE)
Ich bevorzuge oft den standardmäßigen Restfehler der Regression
Das R-Quadrat ist ein leicht verständlicher Bruch. Ich schätze jedoch oft den etwas größeren Fehler, der bei der Regression üblich ist. Ich schätze dieses greifbare Wissen aus den seltenen Einheiten der abhängigen Unterscheidung. Wenn ich ein Regressionsmodell verwende, um Prophezeiungen zu starten, sagt mir S auf einen Blick, ob das Modell genau genug ist oder nicht.
Andererseits hat das R-Quadrat einfach keine Einheiten, und daher erscheint es zweideutig, dass S. Wenn wir nur das R-Quadrat kennen, also 76,1% ohne Fragen, wissen wir nicht, wie groß dieses Modell im Durchschnitt ist basiert auf Fehler. … Um genaue Vorhersagen zu erhalten, benötigen Sie die wichtigste R-Quadrat-Größe, aber Sie können nicht garantieren, wie genau sie sein sollte. Dies liegt daran, dass es schwierig ist, R-Quadrat zu verwenden, um die Genauigkeit und Präzision einiger Vorhersagen abzuschätzen.
Um dies zu demonstrieren, sehen wir uns dieses Regressionsbeispiel an. Nehmen wir an, unsere Gedanken müssen innerhalb von +/- 5% einschließlich dir liegen, damit die beobachteten Werte nützlich werden. Wenn Experten nur das R-Quadrat von 76,1% kennen, kann jemand sagen, ob unser Modell klar genug ist? Nein, das kann man bei einem hervorragenden R-Quadrat nicht sagen.
Sie können jedoch den standardisierten Fehler aufgrund der Regression verwenden. Für unser Modell mit der erforderlichen Genauigkeit darf S nicht mehr als 2,5% betragen, da 2,5 * 2 eine Anzahl von bedeutet. Plötzlich stellen wir fest, dass unser S (3.5) zu groß sein sollte. Brauchen wir ein genaueres Modell. Dankeschön!
Während ich das beliebte Verbleiben sehr ähnlich mag, kann man natürlich jederzeit die perfekte Übereinstimmung in zwei Einheiten gleichzeitig betrachten. Dies ist das mathematische Äquivalent, das verbunden ist, Ihren Kuchen zu essen und ihn zu nehmen!
Wenn Sie neu in der Regression sind und Ihnen die Operation gefällt, die ich in meinem Blog verwende, lesen Sie das Market eBook!
Verknüpft
Verbessern Sie noch heute die Geschwindigkeit Ihres Computers, indem Sie diese Software herunterladen – sie wird Ihre PC-Probleme beheben.
Was sagt Ihnen selbst ein Fehler?
Ein beliebter Fehler sagt Ihnen, wie sicher es ist, dass die Sammlung einer zugewiesenen Probe aus dieser Kolonie mit Ihrem aktuellen Mittelwert für die aktuelle Population verglichen wird. Wenn der Zögerfehler zunimmt, d. h. H. Wenn die Mittelwerte tendenziell größer werden, steigt die Wahrscheinlichkeit, dass die meisten der derzeit gemeldeten Mittelwerte sowie der wahre Mittelwert der Gesellschaft ungenau sind.
Wie interpretieren Sie den normalen Fehler des Mittelwerts?
Der Markenstandardfehler ist das Risiko einer Stichprobentaktik mit Originaleinheiten und Maßabweichungen vom Mittelwert. Auch hier entsprechen höhere Überzeugungen einer breiteren Verteilung. Bei einem SEM von 3 wissen wir, wo die typische Variante zwischen der Stichprobe und dem Mittelwert der Grundgesamtheit 3 sein kann.
Tips For Correcting Standard Errors Indicating Regression
Conseils Pour Corriger Les Erreurs Standard Indiquant Une Régression
Советы по исправлению стандартных ошибок, указывающих на регресс
Wskazówki Dotyczące Korygowania Błędów Standardowych Wskazujących Na Regresję
Dicas Para Corrigir Erros Padrão Que Indicam Regressão
Sugerencias Para Corregir Errores Estándar Que Indican Regresión
Suggerimenti Per Correggere Gli Errori Standard Che Indicano Una Regressione
Tips Eftersom Korrigering Av Standardfel Som Indikerar Regression
회귀를 나타내는 표준 오류 수정을 위한 팁
Tips Voor Het Corrigeren Van Standaardfouten Die Regressie Aangeven

Related posts:
 Hinweise Zur Bestimmung Von 95 Konfidenzintervallen Und Standardfehlern
Hinweise Zur Bestimmung Von 95 Konfidenzintervallen Und Standardfehlern
 Vorschläge Zur Korrektur Von Fehlern Beim Beenden Des Programms
Vorschläge Zur Korrektur Von Fehlern Beim Beenden Des Programms
 Der Einfachste Weg, Um Eine Antiviren-Installation Auf Einem Computer Zu Reparieren, Ohne Einen Sinnvollen Schritt Auf Einem Computer Zu Machen
Der Einfachste Weg, Um Eine Antiviren-Installation Auf Einem Computer Zu Reparieren, Ohne Einen Sinnvollen Schritt Auf Einem Computer Zu Machen
 Gelöst: Vorschläge Zur Korrektur Des Speicherorts Des Benutzerprofilordners In Windows XP
Gelöst: Vorschläge Zur Korrektur Des Speicherorts Des Benutzerprofilordners In Windows XP