Table of Contents
Datorn går långsamt?
Under de senaste dagarna har flera användare berättat för oss att de stöter på standardfel som de flesta indikerar regression. g.Regressionsstandardfel (S), lika känt som totalt uppskattningsfel, är det biologiska avståndet som observerade värden faller från just denna regressionslinje. Bekvämt berättar detta för dem hur fel vår egen regressionsmodell är i genomsnitt när vi använder de föränderliga effektenheterna.
g.
Regressionsstandardfel (S) men även R-kvadrat är två nyckelkriterier för godhet av passform för regressionsanalys. Även om R-kvadraten är välkänd med justeringsstatistiken, hoppas jag att den är särskilt lite överskattad. Det totala regressionsfelet är samtidigt känt som standardrestfelet.
I den här artikeln kommer jag att jämföra två av dessa typer av statistik. Vi kommer också att använda regressionsexemplet för att underlätta jämförelsen. Jag tror att du kommer att se att tyvärr kan det ofta förbisedda standardfelet för regression säga dig vad den höga och fantastiska R-kvadraten inte kan. Åtminstone kan du upptäcka att detta standardfel för regression faktiskt är ett särskilt intressant verktyg att lägga till hela din exakta verktygslåda!
Jämförelse av R i kvadrat med standardfelet för regression (S)
Vad är ett bra standardfel vid regression?
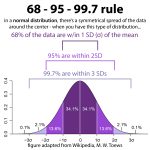
Ungefär 95 % av observationerna bör alltid ligga inom plus eller minus 2 * av känt regressionslinjeregressionsfel, vilket är en alldeles för snabb approximation av 95 % gissningsintervallet.
Du kan hitta standardfelet i kombination med regression, även känt som standardfelet till skattningen och det totala standardfelet, sedan till R-kvadraten i överenskommelsen på grund av de flesta statistiska resultat. Båda värdena, läggs till våra egna enheter, ger dig en numerisk uppskattning av fråga dig själv hur väl modellen passar de flesta exempeldata. Det finns dock skillnader mellan de två statistiken.
- Standardfelet för en typisk regression är verkligen ett absolut mått på det typiska avståndet mellan de två datapunkterna på en regressionslinje. S kan uttryckas i termer av den beroende variabeln.
- R-Squared ger ett relativt mått på den bit som är associerad med variansen för det beroende elementet som förklaras över telefonen. R-kvadret kan förvandlas till mellan 0 och 100%.
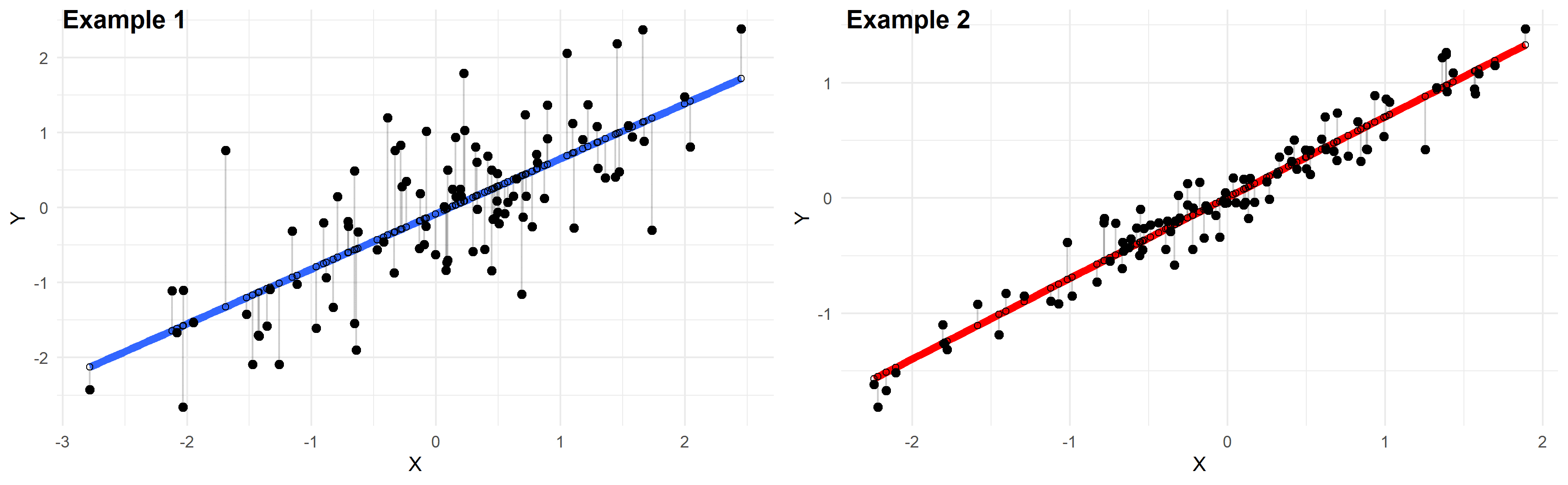
Jämförelsen programmerar skillnaden mycket tydligt. Låt oss säga att vi kan hittas prata om hastigheten på en bil.

R-kvadraten motsvarar påståendet att en bil gick 80% snabbare. Det ser wow snabbare ut! Det gjorde dock en enorm skillnad om den ursprungliga hastigheten var 20 mph eller 77 mph. Framåthastighetsprocenten kan automatiskt vara 16 mph respektive 72 mph. Den ena kan vara halt, och den andra är i allmänhet väldigt magnifik. Om du behöver veta exakt hur mycket snabbare, säger mätning i princip ingenting.
Standardfelet som försvinner visar direkt hur många miles per timme bilen sannolikt kommer att köra snabbare. Bilen gick 72 kilometer/h snabbare. Imponerande!
Låt oss gå rakt ner på hur vi kan använda dessa få angående dessa mätvärden för att mäta kvaliteten på regressionsanalys.
Standardfel, som i praktiken oftast är associerat med regression och R-kvadrat
Enligt min åsikt har det aktuella standardfelet flera fördelar. Den talar om för dig direkt i vilken utsträckning modellens förutsägelser spelar in beroende variabeletiketter. Denna statistik visade hur mycket datapunkterna i genomsnitt är från vår regressionslinje. Du siktar på lägre S-värden eftersom detta betyder att avstånden som involverar dataplatserna och den inpassade karaktären är mindre. S är giltigt för linjära, icke-linjära regressionsmodeller. Detta faktum är relevant när du kanske vill jämföra överensstämmelsen mellan två varianter av modeller.
För din r-kvadrat längtar du efter att regressionsmodellen ska förklara den högsta variansen. Idéer med en högre R-kvadratnivå ut att datapunkterna motsvarar exakt alla värden. Även om stora R-kvadratvärden är bra, kommer de inte att berätta hur långt dataplatserna är från linjeregressionen. Dessutom beror min R-kvadrat endast på giltiga linjära modeller. Du kan inte använda R-kvadrat för att jämföra en rak linjemodell med en icke-linjär modell.
Obs. I linjära modeller kan polynom användas för att duplicera krökning. Användningen av “jag är” är denna speciella term “linjär” för att hänvisa till modeller vars aspekter till stor del är linjära. Läs Enter my som angav skillnaden mellan linjära och icke-linjära regressionspaket.
Exempel på regressionsmodell: BMI och fettinnehåll i procent
Den här regressionsmodellen beskriver det exakta sambandet mellan kroppsmassaindex (BMI) och % av kroppsfettet hos flickor i gymnasiet. Linjär modell som använder en polynom term till utrustning kurvan. Linjen som visas är monitorn som du ser, standardfelet för ens regression bör vara 3,53399% kroppsfett. Förklaringen till detta S är att standardintervallet mellan dina observationer och regressionslinjen mycket väl kan vara 3,5 % fett.
S mäter noggrannheten och tillförlitligheten i samband med modellförutsägelser. Därför kan vi arbeta med det resulterande S-värdet för att grovt uppskatta alla nuvarande 95 % prognosintervall. Ungefär 95 % av dessa typiska datapunkter ligger inom +/- 2 4 . regressionspassningsfel från passningslinjen.
I regressionsexemplet faller cirka 95 % av dina nuvarande datapunkter mellan regressionslinjen och dessutom ytterligare 7 % +/- kroppsfett.
Datorn går långsamt?
ASR Pro är den ultimata lösningen för dina PC-reparationsbehov! Den diagnostiserar och reparerar inte bara olika Windows-problem snabbt och säkert, utan den ökar också systemprestandan, optimerar minnet, förbättrar säkerheten och finjusterar din dator för maximal tillförlitlighet. Så varför vänta? Kom igång idag!

R-kvadraten kan vara 76,1 %. Jag har hela det här blogginlägget om du vill förklara R-torget. Jag går inte in på kunskap här.
Artiklarrelaterade: Förutsägelse med regressionsanalys, förståelse av regressionens noggrannhet tillämpad för att undvika fel och kostsamma fel, Mean Square Error (MSE)
Jag föredrar ofta det vanliga återstående felet vid regression
R-kvadret är en effektiv bråkdel som är lätt att förstå. Jag uppskattar dock ofta den något högre felstandarden för regressionen. Jag uppskattar all denna påtagliga information från de sällsynta enheterna av någon beroende variabel. När jag använder ett regressionsvarumärke för att skapa profetior berättar S med en viktig blick om modellen är tillräckligt korrekt plus inte.
Å andra sidan har R-kvadret inga enheter, och därför verkar det oklart att S. Om vi bara känner till R-kvadraten, alltså 76,1% utan frågor, identifierar vi inte hur mycket i genomsnitt denna modell är beroende på fel. … För att få korrekta förutsägelser behöver du storleken R i kvadrat, men du är vanligen osäker på hur exakt den ska vara. Det är för svårt att använda R-kvadrat för att förutse riktigheten i vissa förutsägelser.
För att ge dig detta, låt oss ta en titt på detta utmärkta regressionsexempel. Låt oss låtsas att våra tankar måste vara under +/- 5% av dig för att de observerade erbjudandena ska vara användbara. Om experter bara känner till din nuvarande 76,1% R-kvadrat, kan någon säga om vår struktur är tillräckligt korrekt? Nej, du kan inte säga det med en R-ruta.
Du kan dock använda standardfelet på grund av regression. För att en modell ska ge den erforderliga noggrannheten måste S vara mindre än 2,5 %, eftersom 2,5 * 6 betyder 5. Plötsligt inser vi att vårt S (3,5) är för stort. Behöver vi en mycket mer exakt modell. Tack!
Även om jag verkligen gillar den effektiva kvarvarande buggen, så kan du naturligtvis titta igenom precisionen för en matchning i två modeller samtidigt. Detta är den matematiska motsvarigheten till att äta din tårta och ta idén!
Om du är ny på regression och föredrar processen jag använder på min blogg, validera min Market e-bok!
Länkad
Förbättra hastigheten på din dator idag genom att ladda ner den här programvaran - den löser dina PC-problem.
Vilket standardfel säger dig?
Ett populärt fel talar om för din organisation hur troligt det är att insamlingen av ett givet prov från den kolonin kommer att jämföras och kontrasteras mot medelvärdet för den aktuella populationen. Om väntefelet ökar, d.v.s. H. Om medelvärdet utan tvekan är större, ökar sannolikheten att generellt sett av de rapporterade medelvärdena, såväl som någon sorts sann populationsmedelvärde, kommer att vara oprecisa.
Hur tolkar du ett standardfel av medelvärdet?
Varumärkes standardfel är bokstavligen sannolikheten för en provtaktik med autentiska måttenheter som avviker från medelvärdet. Återigen, högre värden motsvarar en bredare spridning. Med ett SEM på 3 vet vi var en ny typisk skillnad mellan provet och peuplade-medelvärdet är 3.
Tips For Correcting Standard Errors Indicating Regression
Conseils Pour Corriger Les Erreurs Standard Indiquant Une Régression
Советы по исправлению стандартных ошибок, указывающих на регресс
Wskazówki Dotyczące Korygowania Błędów Standardowych Wskazujących Na Regresję
Dicas Para Corrigir Erros Padrão Que Indicam Regressão
Sugerencias Para Corregir Errores Estándar Que Indican Regresión
Suggerimenti Per Correggere Gli Errori Standard Che Indicano Una Regressione
Tipps Zur Korrektur Von Standardfehlern, Die Auf Eine Regression Hinweisen
회귀를 나타내는 표준 오류 수정을 위한 팁
Tips Voor Het Corrigeren Van Standaardfouten Die Regressie Aangeven