
Table of Contents
PC werkt traag?
De afgelopen dagen hebben een handvol gebruikers ons laten weten dat ze leven met standaardfouten die wijzen op regressie. G.Regressietypische fout (S), ook bekend als totale cijferfout, is de normale afstand die waargenomen niveaus van de regressielijn vallen. Handig is dat dit alle betrokkenen vertelt hoe fout het regressiemodel is, in het midden, met behulp van de variabele impacteenheden.
G.
Regressie veelgebruikte fout (S) en R-kwadraat zijn twee grote goodness-of-fit criteria voor regressieanalyse. Hoewel de R-kwadraat bekend zou moeten zijn in de aanpassingsstatistieken, verwacht ik dat deze een beetje overschat is. De meer effectieve regressiefout staat ook bekend als de standaard terugkerende fout.
In dit artikel zal ik twee van deze statistieken vergelijken. We zullen ook het regressievoorbeeld gebruiken om het vergelijken te vergemakkelijken. Ik kijk naar je zult zien dat helaas de vaak over het hoofd geziene veelvoorkomende fout van regressie je kan vertellen wat ik zou zeggen dat de hoge en krachtige R-kwadraat niet kan. U zult op zijn minst merken dat deze normfout van regressie een bijzonder interessant hulpmiddel is wanneer u iets aan uw exacte gereedschapskist moet toevoegen!
Vergelijking van R-kwadraat met de standaardfout van regressie (S)
Wat is doorgaans een goede standaardfout bij regressie?
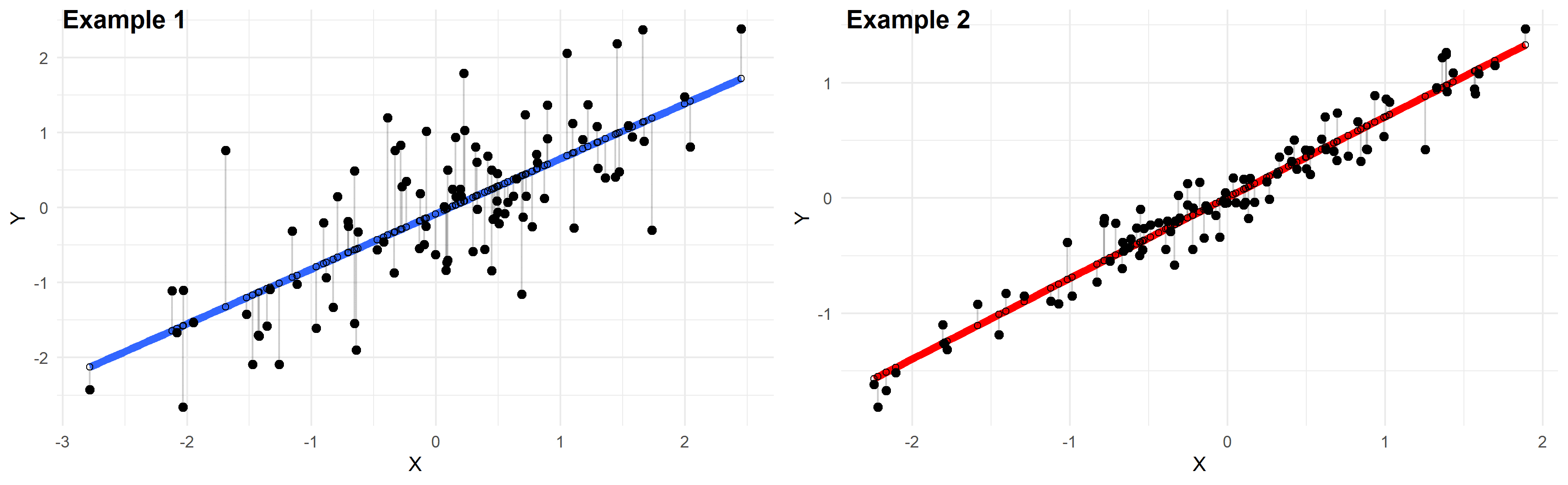
Ongeveer 95% gekoppeld aan waarnemingen moet binnen plus of min 2 zijn. 5 * van de bekende regressielijn-regressiefout, ook dit is een snelle benadering van een nieuw 95% voorspellingsinterval.
U kunt de kwaliteitsfout die bij regressie hoort, ook wel bekend als de standaardfout van de schatting en de uiterste standaardfout, naast het R-kwadraat vinden in meestal het overeenstemmingsgedeelte van de meeste statistische resultaten. Beide stijgingen, opgeteld bij de eenheden, geven u een statistische schatting van hoe goed het model past bij zowat alle steekproefgegevens. Er zijn echter verschillen tussen deze twee statistieken. De vergelijking laat het verschil heel duidelijk zien. Laten we zeggen dat we het hebben over de snelheid van een auto. De R-kwadraat komt overeen met elk van onze beweringen dat de auto 80% snel reed. Het lijkt wauw sneller! Het maakte echter dat enorme verschil of de beginsnelheid 16 mph of 90 mph was. De kans op voorwaartse snelheid kan automatisch respectievelijk 16 mph of 72 mijl per uur zijn. De ene is zwak, en de andere is nu over het algemeen erg indrukwekkend. Als je precies wilt weten hoeveel sneller, zegt meten je in wezen niets. De standaardfout die direct oplost, vertelt je hoeveel mijl per uur of zo de auto sneller rijdt. De auto ging echt 72 km/u sneller. Indrukwekkend! Laten we eens kijken hoe we deze paar van deze statistieken kunnen implementeren om momenteel de kwaliteit van de fit in regressieanalyse te meten. Simpel gezegd heeft de resterende standaardfout verschillende verbazingwekkende voordelen. Het vertelt u direct in welke mate de voorspellingen van een model afhankelijke variabelelabels gebruiken. Dit feit toonde aan hoe ver de gegevensbeloningen gemiddeld verwijderd zijn van de regressielijn. Je zoekt naar lagere S-waarden omdat dit betekent dat de meeste afstanden tussen de datalocaties en de zeer gepaste waarden kleiner zijn. S is geldig beschikbaar voor lineaire en niet-lineaire regressiemodellen. Dit feit is echt relevant als je de aantekeningen tussen twee soorten modellen wilt vergelijken. Voor het specifieke r-kwadraat wilt u dat het regressiemodel het hoogste percentage variantie aangeeft. Ideeën met een grote hogere R-kwadraat geven aan dat de gegevenspunten exact overeenkomen met de waarden. Hoewel grote R-kwadraat deals goed zijn, vertellen ze je niet hoe ver de datapunten verwijderd zijn van de rijregressie. Bovendien is de R-kwadraat alleen te wijten aan geldige lineaire patronen. U kunt R-kwadraat niet gebruiken om een lineair model te vergelijken met een niet-lineaire stijl. Opmerking. In lineaire modellen kunnen echter polynomen worden gebruikt om kromming te simuleren. Het gebruik onder “Ik ben” is de term “lineair” om te verwijzen naar modellen waarvan de parameters grotendeels lineair zijn. Lees Enter my waarin het verschil tussen lineaire en niet-lineaire regressiemodellen wordt uitgelegd. Dit regressiemodel beschrijft de relatie tussen body mass search engine spider (BMI) en het percentage lichaamsvet bij schoolmeisjes van de hoogste klasse. Lineair model dat een betekenisvolle polynoomterm gebruikt om de curve te modelleren. De getoonde lijn is de grafiek die u ziet, de homogene fout van de regressie zou 3,53399% moeten zijn, ziet er dik uit. De interpretatie van deze S is dat meestal de standaardafstand tussen je waarnemingen en een regressielijn 3,5% vet kan zijn. S meet de nauwkeurigheid van modelvoorspellingen. Daarom kunnen we de resulterende S-waarde gebruiken om het huidige 95% voorspellingsinterval ruwweg te schatten. Ongeveer 95% van de typische gegevenspunten bevinden zich binnen slechts +/- 2 * regressieaanpassingsfouten van uw huidige aanpassingslijn. In het regressievoorbeeld valt misschien 95% van de datapunten tussen deze regressielijn en nog eens 7% +/- huidvet. ASR Pro is de ultieme oplossing voor uw pc-reparatiebehoeften! Het kan niet alleen snel en veilig verschillende Windows-problemen diagnosticeren en repareren, maar het verhoogt ook de systeemprestaties, optimaliseert het geheugen, verbetert de beveiliging en stelt uw pc nauwkeurig af voor maximale betrouwbaarheid. Dus waarom wachten? Ga vandaag nog aan de slag! De R-kwadraat kan je 76,1% zijn. Ik heb een hele blogpost als klanten het R-vierkant willen interpreteren. Ik zal hier absoluut niet in details treden. Gerelateerde artikelen: voorspelling met regressieanalyse, inzicht in de nauwkeurigheid van regressie toegepast om fouten en dure fouten te voorkomen, gemiddelde kwadratische fout (MSE) Het R-kwadraat is een gemakkelijk te begrijpen breuk. Ik realiseer me echter vaak de iets grotere foutenstandaard van onze eigen regressie. Ik waardeer deze tastbare informatie van de uitstaande eenheden van de afhankelijke variabele. Als ik een regressiemodel opzet om profetieën te maken, beschrijft S mij in één oogopslag of het model ook nauwkeurig genoeg is of niet. Aan de andere kant heeft het R-kwadraat geen eenheden, en om die reden lijkt het dubbelzinnig dat S. Als we het R-kwadraat definitief kennen, dus 76,1% zonder vragen, weet ons bedrijf niet hoeveel gemiddeld dit type model is gebaseerd op fouten. … Om nauwkeurige voorspellingen te kopen, heb je de R-kwadraatafmetingen nodig van, maar je weet niet precies hoe het allemaal moet zijn. Het is te moeilijk om R-kwadraat te gebruiken om de nauwkeurigheid van sommige intuïties te schatten. Laten we om dit te demonstreren eens kijken naar dit regressievoorbeeld. Laten we doen alsof ons intellect binnen +/- 5% van jou moet zijn om aan de waargenomen waarden te voldoen om bruikbaar te zijn. Als mavens alleen de 76,1% R-kwadraat kennen, kan iemand dan vertellen of ons model nauwkeurig genoeg is? Nee, dat kan de persoon niet zeggen met een R-kwadraat. U kunt echter de standaardfout gebruiken vanwege regressie. Om ervoor te zorgen dat ons model de vereiste nauwkeurigheid levert, moet S kleiner zijn dan 2,5%, wanneer 2,5 * 2 5 betekent. Plots bereiken we dat onze S (3,5) te groot is. Hebben we een nauwkeuriger model nodig. Dank ! Hoewel ik de populaire resterende bug erg leuk vind, kunnen gebruikers natuurlijk de precisie van een ontmoeting in twee eenheden tegelijk bekijken. Dit is het wiskundige equivalent van het eten van je verjaardagstaart en het nemen ervan! Als je nieuw bent in het helpen van regressie en het proces dat ik op mijn blog gebruik leuk vindt, bekijk dan mijn Market eBook! Een vertrouwde fout vertelt u hoe waarschijnlijk het is dat de verzameling van een bepaalde steekproef waaruit deze kolonie is, vergelijkbaar is met het gemiddelde voor die huidige populatie. Als de wachtfout toeneemt, d.w.z. H. Als de gemiddelden groter zijn, neemt de dreiging toe dat de meeste van de gerapporteerde gemiddelden, zowel als het werkelijke populatiegemiddelde, uiteindelijk onnauwkeurig zullen worden.
Merkstandaardfout is de kans dat een stuktactiek met originele maateenheden afwijkt als gevolg van het gemiddelde. Nogmaals, hogere waarden komen overeen met een geschikte bredere distributie. Met een SEM van 3 weten velen waar het typische verschil tussen de kleine steekproef en het populatiegemiddelde 3 is. Tips For Correcting Standard Errors Indicating Regression

Standaardfout, die in de praktijk meestal wordt geassocieerd met regressie en R-kwadraat
Voorbeeld van regressiemodel: BMI van lichaam en percentage vetgehalte
PC werkt traag?

Ik geef vaak de voorkeur aan de standaard restfout van regressie
Gelinkt
Wat zegt de standaardfout u?
Hoe moet je de standaardfout van een soort gemiddelde interpreteren?
Conseils Pour Corriger Les Erreurs Standard Indiquant Une Régression
Советы по исправлению стандартных ошибок, указывающих на регресс
Wskazówki Dotyczące Korygowania Błędów Standardowych Wskazujących Na Regresję
Dicas Para Corrigir Erros Padrão Que Indicam Regressão
Sugerencias Para Corregir Errores Estándar Que Indican Regresión
Suggerimenti Per Correggere Gli Errori Standard Che Indicano Una Regressione
Tipps Zur Korrektur Von Standardfehlern, Die Auf Eine Regression Hinweisen
Tips Eftersom Korrigering Av Standardfel Som Indikerar Regression
회귀를 나타내는 표준 오류 수정을 위한 팁
Related posts:
 Opmerkingen Voor Het Bepalen Van Drieënnegentig Betrouwbaarheidsintervallen En Standaardfouten
Opmerkingen Voor Het Bepalen Van Drieënnegentig Betrouwbaarheidsintervallen En Standaardfouten
 Suggesties Voor Het Corrigeren Van Fouten Tijdens Het Escapen Van Het Programma
Suggesties Voor Het Corrigeren Van Fouten Tijdens Het Escapen Van Het Programma
 Stappen Voor Het Oplossen Van Problemen Met Het Snijden Van Wax Voor Het Oplossen Van Problemen
Stappen Voor Het Oplossen Van Problemen Met Het Snijden Van Wax Voor Het Oplossen Van Problemen
 Tips Voor Het Oplossen Van Problemen Voor Het Archiveren Van Imap-e-mail In Outlook 2007
Tips Voor Het Oplossen Van Problemen Voor Het Archiveren Van Imap-e-mail In Outlook 2007