Table of Contents
PC running slow?
Over the past few days, several users have informed us that they are encountering standard errors that indicate regression. g.Regression standard error (S), also known as total estimate error, is the normal distance that observed values fall from the regression line. Conveniently, this tells them how wrong the regression model is, on average, using the variable impact units.
g.
Regression standard error (S) and R-squared are two key goodness-of-fit criteria for regression analysis. Although the R-squared is well known in the adjustment statistics, I hope it is a little overestimated. The total regression error is also known as the standard residual error.
In this article, I will compare two of these statistics. We’ll also use the regression example for ease of comparison. I think you’ll see that, unfortunately, the often overlooked standard error of regression can tell you what the high and powerful R-squared cannot. At the very least, you will find that this standard error of regression is an especially interesting tool to add to your exact toolbox!
Comparison Of R Squared With The Standard Error Of Regression (S)
What is a good standard error in regression?
About 95% of observations should be inwithin plus or minus 2 * of the known regression line regression error, which is also a fast approximation of the 95% prediction interval.
You can find the standard error associated with regression, also known as the standard error of the estimate and the total standard error, next to the R-square in the agreement section of most statistical results. Both values, added to the units, give you a numerical estimate of how well the model fits most sample data. However, there are differences between the two statistics.
- The standard error of a typical regression is an absolute measure of the typical distance between data points on a regression line. S is expressed in terms of the dependent variable.
- R-Squared provides a relative measure of the percentage associated with the variance of the dependent variable explained over the phone. The R-square can be between 0 and 100%.
The comparison shows the difference very clearly. Let’s say we are talking about the speed of a car.

The R-square corresponds to the statement that the car was going 80% faster. It seems wewow faster! However, it made a huge difference whether the initial speed was 20 mph or 90 mph. The forward speed percentage can automatically be 16 mph or 72 mph, respectively. One is lame, and the other is generally very impressive. If you need to know exactly how much faster, measurement essentially doesn’t tell you anything.
The standard error that disappears directly tells you how many miles per hour the car is moving faster. The car was going 72 km / h faster. Impressive!
Let’s get down to how we can use these few of these metrics to measure the quality of fit in regression analysis.
Standard Error, Which In Practice Is Most Often Associated With Regression And R-squared
In my opinion, the remaining standard error has several advantages. It tells you directly to what extent the model’s predictions use dependent variable labels. This statistic showed how far, on average, the data points are from the regression line. You are aiming for lower S values because thiso means that the distances between the data locations and the fitted values are smaller. S is valid for linear and non-linear regression models. This fact is relevant when you want to compare the correspondence between two types of models.
For your r-squared, you want the regression model to explain the highest percentage of variance. Ideas with a higher R-squared indicate that the data points correspond exactly to the values. While large R-squared values are good, they don’t tell you how far the data points are from the line regression. In addition, the R-squared is due only to valid linear patterns. You cannot use R-squared to compare a linear model with a non-linear model.
Note. In linear models, polynomials can be used to simulate curvature. The use of “I am” is the term “linear” to refer to models whose parameters are largely linear. Read Enter my which explains the difference between linear and non-linear regression models.
Regression Model Example: Body BMI And Percentagefat Content
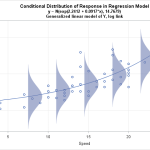
This regression model describes the relationship between body mass index (BMI) and percentage of body fat in high school girls. Linear model that uses a polynomial term to model the curve. The line shown is the graph that you see, the standard error of the regression should be 3.53399% body fat. The interpretation of this S is that the standard distance between your observations and the regression line can be 3.5% fat.
S measures the accuracy associated with model predictions. Therefore, we can use the resulting S value to roughly estimate the current 95% forecast interval. Approximately 95% of the typical data points are within +/- 2 * regression fit errors from the fit line.
In the regression example, approximately 95% of the data points fall between the regression line and an additional 7% +/- body fat.
PC running slow?
ASR Pro is the ultimate solution for your PC repair needs! Not only does it swiftly and safely diagnose and repair various Windows issues, but it also increases system performance, optimizes memory, improves security and fine tunes your PC for maximum reliability. So why wait? Get started today!

The R-squared can be 76.1%. I have a whole blog post if you want to interpret the R-square. I will not go into details here.
ArticlesRelated: Prediction with Regression Analysis, Understanding the Accuracy of Regression Applied to Avoid Errors and Costly Errors, Mean Square Error (MSE)
I Often Prefer The Standard Residual Error Of Regression
The R-square is an easy-to-understand fraction. However, I often appreciate the slightly larger error standard of the regression. I appreciate this tangible information from the rare units of the dependent variable. When I use a regression model to create prophecies, S tells me at a glance whether the model is accurate enough or not.
On the other hand, the R-square has no units, and therefore it seems ambiguous that S. If we only know the R-square, hence 76.1% without questions, we do not know how much on average this model is based on error. … To get accurate predictions, you need the R squared size, but you are not sure how exactly it should be. It is too difficult to use R-squared to estimate the accuracy of some predictions.
To demonstrate this, let’s take a look at this regression example. Let’s pretend thatour thoughts must be within +/- 5% of you for the observed values to be useful. If experts only know the 76.1% R-squared, can anyone tell if our model is accurate enough? No, you can’t say that with an R-square.
However, you can use the standard error due to regression. For our model to provide the required accuracy, S must be less than 2.5%, because 2.5 * 2 means 5. Suddenly, we realize that our S (3.5) is too large. Do we need a more accurate model. Thank you!
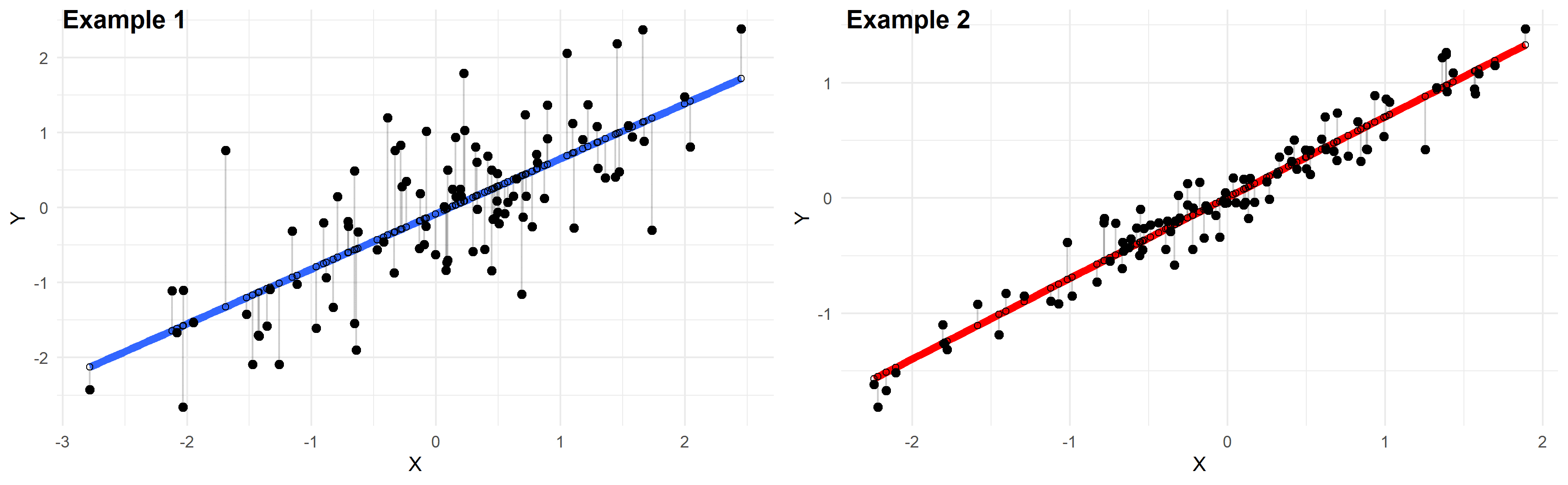
While I really like the popular remaining bug, of course you can look at the precision of a match in two units at the same time. This is the mathematical equivalent of eating your cake and taking it!
If you’re new to regression and like the process I’m using on my blog, check out my Market eBook!
Linked
Improve the speed of your computer today by downloading this software - it will fix your PC problems.
What does standard error tell you?
A popular error tells you how likely it is that the collection of a given sample from that colony will compare to the mean for the current population. If the wait error increases, i.e. H. If the means are larger, the likelihood increases that most of the reported means, as well as the true population mean, will be imprecise.
How do you interpret the standard error of the mean?
Brand standard error is the probability of a sample tactic with original units of measure deviating from the mean. Again, higher values correspond to a wider distribution. With an SEM of 3, we know where the typical difference between the sample and the population mean is 3.
Conseils Pour Corriger Les Erreurs Standard Indiquant Une Régression
Советы по исправлению стандартных ошибок, указывающих на регресс
Wskazówki Dotyczące Korygowania Błędów Standardowych Wskazujących Na Regresję
Dicas Para Corrigir Erros Padrão Que Indicam Regressão
Sugerencias Para Corregir Errores Estándar Que Indican Regresión
Suggerimenti Per Correggere Gli Errori Standard Che Indicano Una Regressione
Tipps Zur Korrektur Von Standardfehlern, Die Auf Eine Regression Hinweisen
Tips Eftersom Korrigering Av Standardfel Som Indikerar Regression
회귀를 나타내는 표준 오류 수정을 위한 팁
Tips Voor Het Corrigeren Van Standaardfouten Die Regressie Aangeven