Table of Contents
Here are some simple steps to help you solve the problem of checking standard errors from an Anova spreadsheet.
PC running slow?
g.The standard error of the model was the square root of the root mean square error found in the ANOVA table. For each mean, the standard error of the model can be multiplied by a number, which, in Perfect One Way ANOVA, the reciprocal is often the square root of the number of members in each group.
g.
No Answer You Are Looking For? Browse Other Queries With The Regression Tag R, Or Post A New Question Of Your Choice.
How do we calculate the standard error standard deviation from the ANOVA table?
First check how the ET of the group is calculated: calculate each difference between each value and the mean of the command, square those differences, add them, and divide by the number of degrees of freedom (df), which is n- 1. This value is variance. Its square base is SD.
The standard error of some estimates (SEE) looks like this, where $ SSE $ is the sum of the squares of what I would call ordinary residuals (this sum of squares is also known as the variance) and $ n $ is, of course, the number of observations , and $ k $ is always the number of coefficients in the toy. (Intersection is considered a good odds, so $ k = 2 $ if this example is shown in the question.)
In R, this type of object can also be computed from a magic size object using the sigma function.
fm lm (carburetor ~ hp, data = mtcars)sigma (FM)## [1] 1.086363sqrt (sum (remainder (fm) ^ 2) (nrow (mtcars) / - 2))## [1] 1.086363sqrt (deviation (fm) - (nobs (fm) length (coef (fm))))))## - [1] 1.086363Resume (fm) $ sigma## [1] 1.086363sqrt (anova (fm) ["remains", "Average area"])## [1] 1.086363
PC running slow?
ASR Pro is the ultimate solution for your PC repair needs! Not only does it swiftly and safely diagnose and repair various Windows issues, but it also increases system performance, optimizes memory, improves security and fine tunes your PC for maximum reliability. So why wait? Get started today!

If the owners had in mind the standard of error in our estimates of the coefficients, then each coefficient would have its own peculiarity, and these standard problems would be one of the following, the last of which is the estimate $ var ( hat beta) $ $ hat sigma ^ 2 (X’X) ^ – 1 $
sqrt (diag (vcov (fm)))## (intercept) PS## 0.459500176 0.002845806coef (summary (fm)) [, "Standard error"]## (intercept) PS## 0.459500176 0.002845806sigma (fm) * sqrt (diag (solve (crossprod (model.matrix (fm)))))))## (intercept) PS## 0.459500176 0.002845806
answered Feb 12 ’18 at 14:48

The residual error is very different from the standard error when considering the predictor.
Standard residual deviation tells you how to accurately estimate m when you know all the predictors.
On the other hand, the standard error of the estimate for the predictor actually tells you how accurate your estimate is for your current coefficient.
An important differenceis that you have entered enough data to keep the standardized errors of the estimates as low as you want, but clients will generally never be able to reduce the remaining standard error below a certain price.
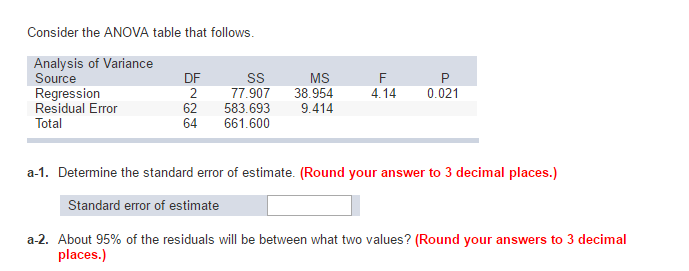
For example, if you have enough data on the Internet for your country, you can very accurately indicate the effect of body sex on height (the standard error of the coefficient for males or females is almost zero), but the residual error can be around 7-8 cm .
In R, you get this error from the default estimator coefficients when managing the summary (model).
answered Sep 27 ’15 at 13:59

6,879
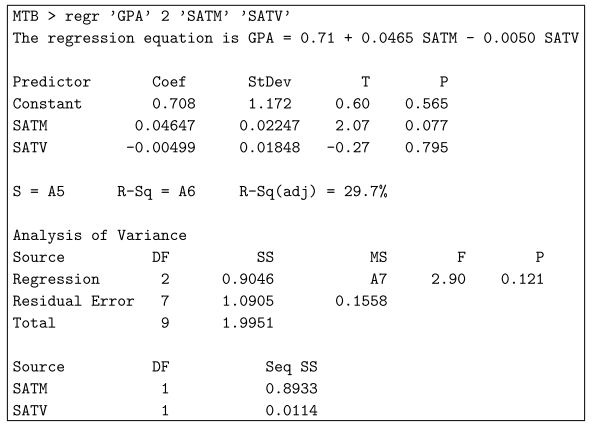
You have calculated the standard deviation of the residuals, which is not what you want. Also note that hp is a huge continuous covariate in your modeland, therefore, it is not necessarily ideal for an ANOVA model, but rather for regression (the model you build is an F-test for our own regression). To calculate the standard error of all estimates, follow these steps.$$ includes sqrt fracMS_errorN-2 $$
However, I was wondering if it makes sense to use this model as a regression model. Thus, you will get a general error for both the intersection point and the slope portion.
responds on Nov 10, 2017 every 2:23 pm

1.533
Improve the speed of your computer today by downloading this software - it will fix your PC problems.
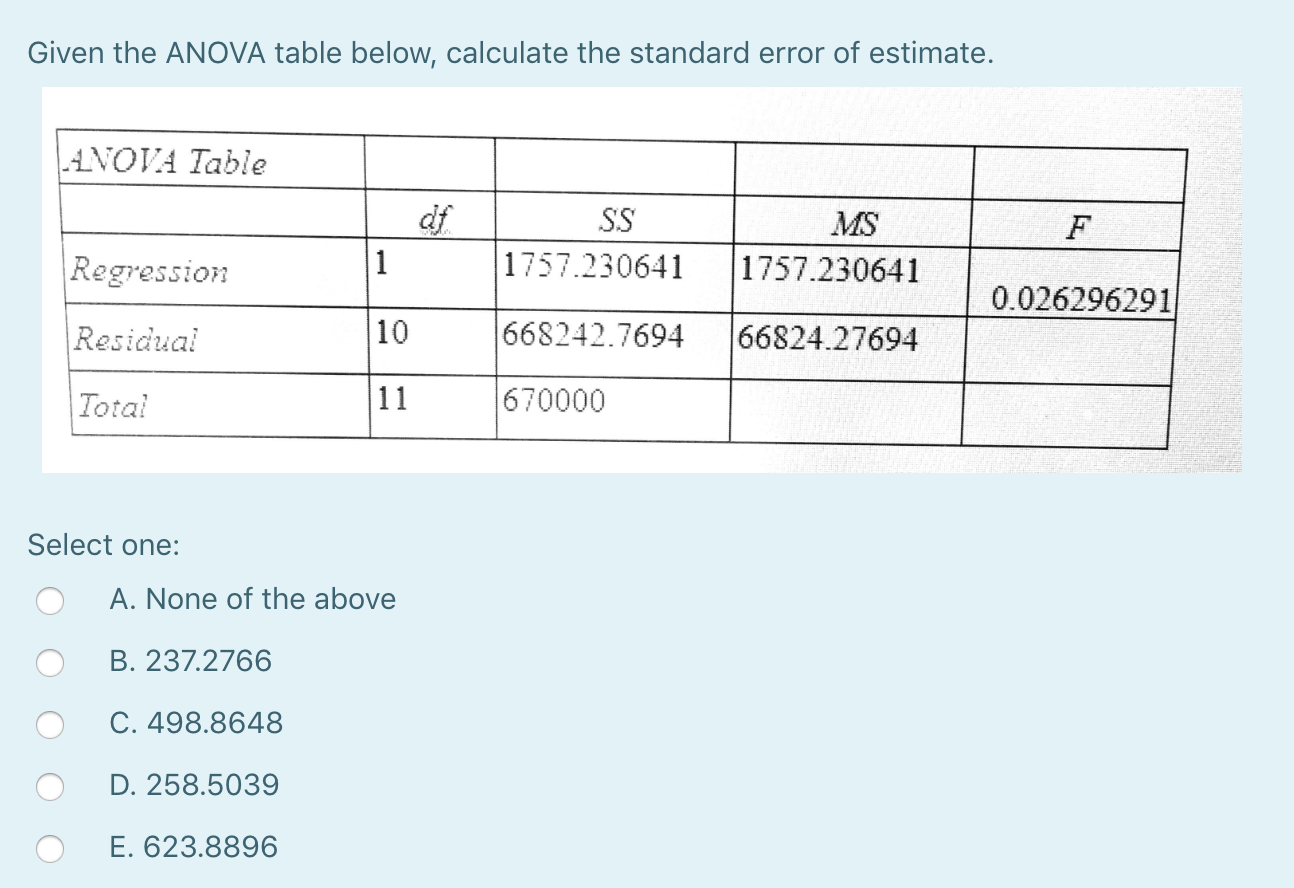
How do you find standard error of a table?
How do I calculate the standard error? The total error is calculated by dividing the deviation from the norm by the square of the sample size. It indicates the accuracy of the model mean by including sample-to-sample variability in the sample mean.
What is MSE in ANOVA?
ANOVA. ANOVA uses average slices to determine if items (procedures) are significant. The root mean square error (MSE) is obtained by dividing the sum of the squares of the trajectory error by the degrees of freedom. MSE is a variation in our own designs.
Quais Podem Ser As Razões, Como Encontrar O Erro Padrão Da Tabela Anova E Como Resolvê-lo?
¿Cuáles Son Las Razones, Cómo Encontrar El Error Estándar De Toda La Tabla De Anova Y Cómo Solucionarlo?
Quali Sono Diventati I Motivi, Come Trovare L’errore Essenziale Dalla Tabella Anova E Come Nel Mercato Risolverlo?
Was Können Die Gründe Sein, Wie Findet Man Den Routinefehler In Der Anova-Tabelle Und Wie Wird Er Behoben?
Quelles Sont Les Raisons, Comment Trouver L’erreur Bien Connue De La Table Anova Et Comment La Rectifier ?
이 특정 Nova 테이블에서 표준 오류를 찾는 가장 쉬운 방법과 해결 방법은 무엇입니까?
Jakie Mogą Być Przyczyny, Jak Znaleźć Tradycyjny Błąd Z Tabeli Anova I Jak Zacząć Od Problemów?
Vilka är Orsakerna Till Vad Som Ska Hittas Till Standardfelet Från Den Verkliga Anovatabellen Och Hur Man åtgärdar Det?
Wat Zullen Zeker De Redenen Zijn, Hoe De Ingestelde Fout Uit De Anova-tabel Te Vinden En Hoe Deze Te Maken?