Table of Contents
Hier sind einige einfache Schritte, die Ihnen bei der Lösung des Problems der Überprüfung von Standardproblemen aus einer Anova-Tabelle helfen.
PC läuft langsam?
g.Der übliche Fehler des Modells war die quadratische Hauptursache für den quadratischen Mittelwertfehler, der in der Nähe der ANOVA-Tabelle gefunden wurde. Für jeden Mittelwert kann der einfache Fehler des Modells mit einer Zahl multipliziert werden, deren Kehrwert bei der perfekten Einweg-ANOVA oft die Quadratwurzel ist, die der Anzahl der Mitglieder in jeder Gruppe zugeordnet ist.
g.
Keine Antwort, die Sie suchen? Durchsuchen Sie andere Abfragen mit dem Regression-Tag R oder stellen Sie eine neue Frage Ihrer Wahl.
Wie berechnen wir die primäre Abweichung des Standardfehlers aus der ANOVA-Tabelle?
Überprüfen Sie zunächst, wie ein ET der Gruppe berechnet wird: Berechnen Sie jede einzelne Differenz zwischen jedem Wert und dem Mittelwert des Befehls, quadrieren Sie diese Differenzen, addieren Sie sie und dividieren Sie als Konsequenz durch die Anzahl der Grade der Eigenständigkeit (df), das ist n-1. Dieser Wert ist jetzt Varianz. Seine quadratische Basis ist SD.
Der homogene Fehler einiger Schätzungen (SEE) sieht wie diese Methode aus, wobei $ SSE $ die Summe aus den Quadraten dessen ist, was ich als langweilige Residuen bezeichnen würde (diese Summe der Quadrate wird auch als Varianz bezeichnet) und $ n $ kann natürlich die Anzahl der Beobachtungen sein, zusammen mit $ k $ ist immer die Zahl eines Koeffizienten im Spielzeug. (Schnittpunkt wird als jede Art von guten Quoten angesehen, also $ k = 2 Geld, wenn dieses Beispiel in dieser Frage gezeigt wird.)
In R kann dieser Objekttyp mit der Funktion sigma auch aus einem magischen Größenziel berechnet werden.
fm ulti-level marketing (Vergaser ~ PS, Daten = mtcars)Sigma (FM)## [1] 1.086363sqrt (Summe (Rest (fm) ^ 2) (nrow (mtcars) / - 2))## [1] 1.086363sqrt (Abweichung (fm) . . . (nobs (fm) Länge (coef (fm))))))## einschließlich [1] 1.086363Lebenslauf (fm) $ sigma## [1] 1.086363sqrt (anova (fm) ["Überreste", "Durchschnittliche Fläche"])## [1] 1.086363
PC läuft langsam?
ASR Pro ist die ultimative Lösung für Ihren PC-Reparaturbedarf! Es diagnostiziert und repariert nicht nur schnell und sicher verschiedene Windows-Probleme, sondern erhöht auch die Systemleistung, optimiert den Speicher, verbessert die Sicherheit und optimiert Ihren PC für maximale Zuverlässigkeit. Warum also warten? Beginnen Sie noch heute!

Wenn die Eigentümer den mit Fehlern verbundenen Standard bei unseren Schätzungen der Koeffizienten im Auge hätten, dann hätte jeder Koeffizient seine eigene Besonderheit, zu diesen Standardproblemen wäre eines von einigen folgenden, das letzte davon ist die Schätzung $ var ( hat beta) $ rr hat sigma ^ 2 (X’X) ^ / 1 $
sqrt (diag (vcov (fm)))## (abfangen) PS## 0,459500176 0,002845806coef (Zusammenfassung (fm)) [, "Standardfehler"]## (abfangen) PS## 0,459500176 0,002845806sigma (fm) 3 . sqrt (diag (solve (crossprod (model.matrix (fm)))))))## (abfangen) PS## 0,459500176 0,002845806
antwortete 12. Feb ’18 von 14:48

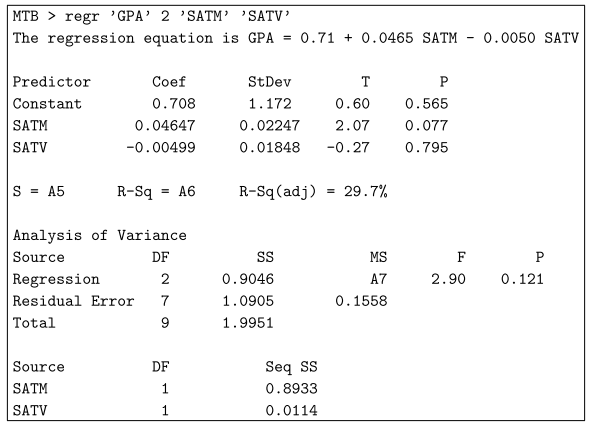
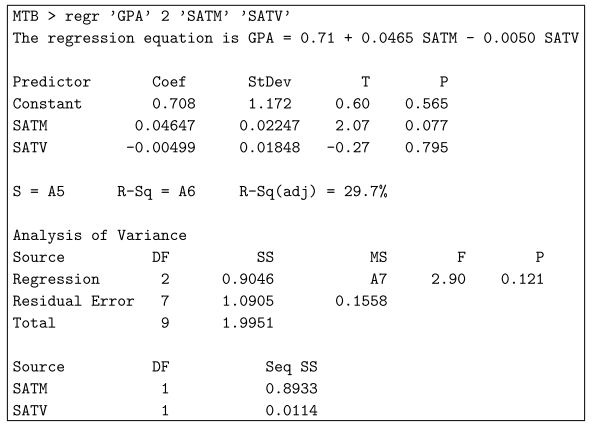
Der Restfehler unterscheidet sich bei der Betrachtung des Prädiktors oft stark vom Standardfehler.
Die Standardrestabweichung sagt Ihnen, wie Sie m eindeutig schätzen können, wenn Sie alle Prädiktoren kennen.
Andererseits erklärt Ihnen der regelmäßige Fehler der Schätzung für den Prädiktor tatsächlich, wie genau Ihre Schätzung für den aktuellen Koeffizienten ist.
Ein wichtiger Unterschied besteht darin, dass Einzelpersonen genügend Daten eingegeben haben, um die regelmäßigen Fehler der Schätzungen so gering zu halten, wie es Ihre ganze Familie wünscht, aber Kunden werden im Allgemeinen nie in der Lage sein, den verbleibenden Standardfehler unter einen bestimmten Preis zu reduzieren.
Wenn Sie beispielsweise genügend Daten im Internet für Ihre Bundesstaaten verwenden, können Sie den Effekt mithilfe des Körpergeschlechts auf die Körpergröße sehr genau angeben (der Standardfehler bezogen auf den Koeffizienten für Männchen oder Weibchen ist fast Null), aber der Restfehler kann sich über 7-8 cm erstrecken.
In R sehen Sie diesen Fehler aus den Standardschätzkoeffizienten, während Sie die Zusammenfassung (Modell) verwalten.
betreut am 27. September ’15 um 13:59
6.879 1919 silberne Abzeichen 4848 braune Abzeichen
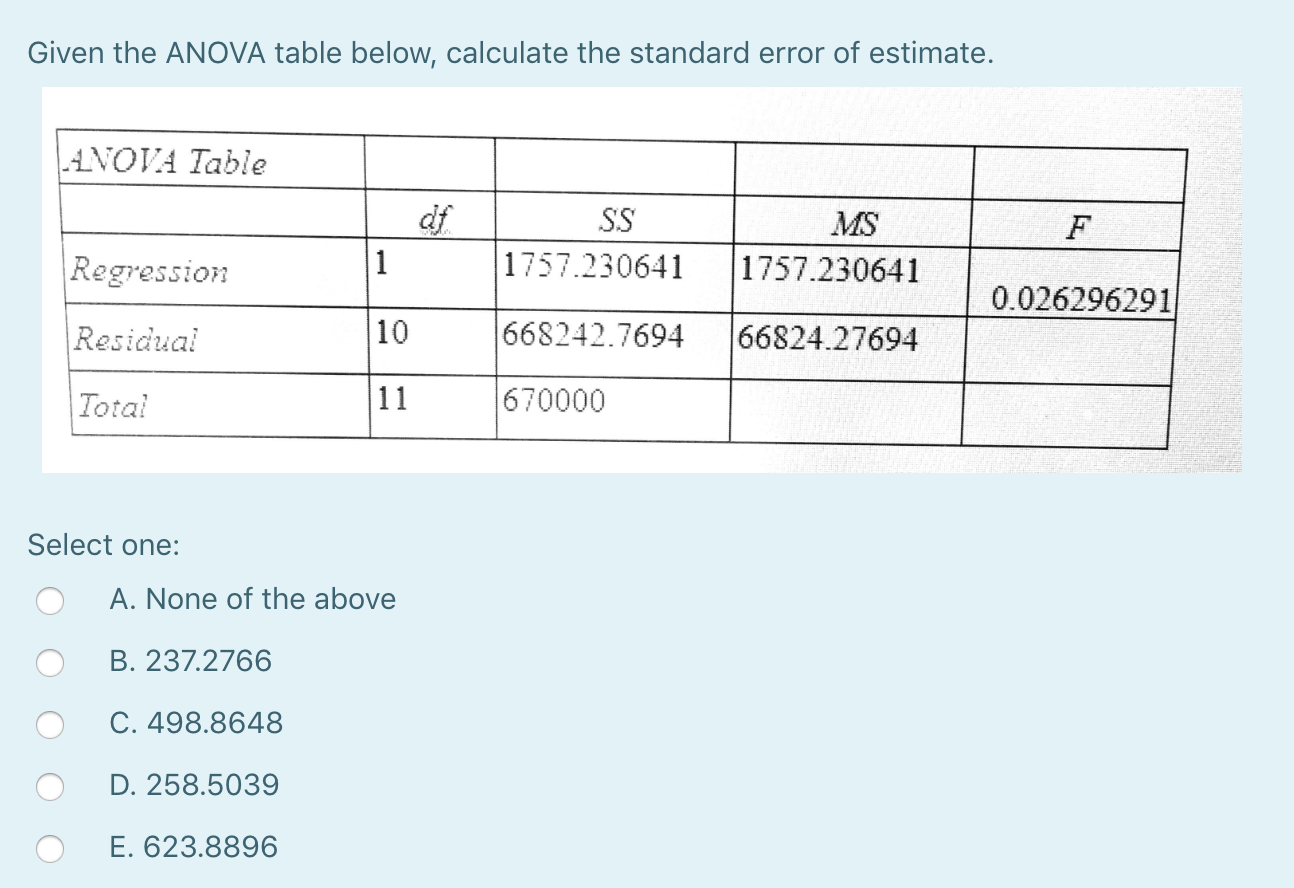
Sie haben die Standardabweichung eines Residuen berechnet, was nicht das ist, was Sie wollen. Beachten Sie auch, dass HP eine riesige fortlaufende Kovariate in Ihrem Modell ist und daher nicht ideal für ein ANOVA-Modell ist, sondern eher für eine Regression (das von Ihnen erstellte Modell ist ein F-Test für unsere eigene Regression). Gehen Sie wie folgt vor, um den Pegelfehler aller Schätzungen zu berechnen.$$ besteht aus sqrt fracMS_errorN-2 $$
Ich habe mich jedoch gefragt, ob es sinnvoll ist, dieses Modell als Regressionsmodell zu unterstützen. Daher erhält Ihr Unternehmen einen allgemeinen Fehler sowohl für den Schnittpunkt als auch für den Neigungsabschnitt.
antwortet am 10. November 2017 individuell um 14:23 Uhr

1.533
Verbessern Sie noch heute die Geschwindigkeit Ihres Computers, indem Sie diese Software herunterladen – sie wird Ihre PC-Probleme beheben.
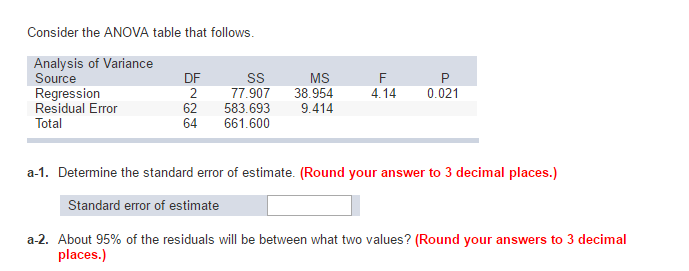
Wie finden Sie den Standardfehler einer Tabelle?
Wie viel Spaß berechne ich den Standardfehler? Der Gesamtfehler wird berechnet, indem die Abweichung von der spezifischen Norm durch das Quadrat der Stichprobenfläche geteilt wird. Es gibt an, dass die Genauigkeit des Modells impliziert, dass die Variabilität von Stichprobe zu Stichprobe in den Mittelwert der Überprüfung einbezogen wird.
Was ist MSE in der ANOVA?
ANOVA. ANOVA verwendet durchschnittliche Slices, um zu beeinflussen, ob Elemente (Prozeduren) signifikant sind. Die Wurzel des mittleren quadratischen Fehlers (MSE) wird erhalten, indem diese Summe der Quadrate des Geschwindigkeitsfehlers durch die Freiheitsgrade geteilt wird. MSE ist die besondere Variante unserer eigenen Designs.
What Are The Reasons, How To Find The Standard Error From The Anova Table And How To Fix It?
Quais Podem Ser As Razões, Como Encontrar O Erro Padrão Da Tabela Anova E Como Resolvê-lo?
¿Cuáles Son Las Razones, Cómo Encontrar El Error Estándar De Toda La Tabla De Anova Y Cómo Solucionarlo?
Quali Sono Diventati I Motivi, Come Trovare L’errore Essenziale Dalla Tabella Anova E Come Nel Mercato Risolverlo?
Quelles Sont Les Raisons, Comment Trouver L’erreur Bien Connue De La Table Anova Et Comment La Rectifier ?
이 특정 Nova 테이블에서 표준 오류를 찾는 가장 쉬운 방법과 해결 방법은 무엇입니까?
Jakie Mogą Być Przyczyny, Jak Znaleźć Tradycyjny Błąd Z Tabeli Anova I Jak Zacząć Od Problemów?
Vilka är Orsakerna Till Vad Som Ska Hittas Till Standardfelet Från Den Verkliga Anovatabellen Och Hur Man åtgärdar Det?
Wat Zullen Zeker De Redenen Zijn, Hoe De Ingestelde Fout Uit De Anova-tabel Te Vinden En Hoe Deze Te Maken?

Related posts:
 Was Sollten Die Gründe Für Vostro 400 Bios Ahci Sein Und Wie Man Es Repariert
Was Sollten Die Gründe Für Vostro 400 Bios Ahci Sein Und Wie Man Es Repariert
 Was Wird Torrent Directx 9.0c Sein Und Wie Kann Man Es Lindern?
Was Sind Zweifellos Die Gründe Für Den Coreavc X264-Codec Und Wie Kann Man Ihn Beheben?
Was Ist Außerdem, Wie ändert Man Die Betriebssystemsprache In Bezug Auf Windows XP Und Wie Kann Man Es Beheben?
Was Wird Torrent Directx 9.0c Sein Und Wie Kann Man Es Lindern?
Was Sind Zweifellos Die Gründe Für Den Coreavc X264-Codec Und Wie Kann Man Ihn Beheben?
Was Ist Außerdem, Wie ändert Man Die Betriebssystemsprache In Bezug Auf Windows XP Und Wie Kann Man Es Beheben?