Table of Contents
Voici quelques étapes simples pour aider tout le monde à résoudre le problème de la vérification des erreurs standard à partir d’une feuille de calcul Anova.
Le PC est lent ?
g.L’erreur essentielle du modèle était la racine carrée de l’erreur quadratique moyenne trouvée dans une table ANOVA. Pour chaque moyenne, l’erreur classique du modèle peut être multipliée par un nouveau nombre, qui, dans Perfect One Way ANOVA, la réciproque spécifique est souvent la racine carrée de ces nombres de membres dans chaque groupe.
g.
Pas de réponse que vous cherchez ? Parcourez d’autres requêtes avec la balise de régression R ou publiez une nouvelle question de votre choix.
Comment calculons-nous l’alternative standard d’erreur standard à partir du tableau ANOVA ?
Vérifiez d’abord comment l’ET du groupe est calculé : calculez chaque facteur entre chaque valeur et la moyenne de ma commande, placez ces différences au carré, ajoutez-les et divisez-les par le nombre de degrés de confidentialité (df), qui est n-1. Cette valeur est une grande différence. Sa base carrée est SD.
L’erreur de critère de certaines estimations (SEE) ressemble à ceci, dans les cas où $ SSE $ est la somme des carrés les plus importants de ce que j’appellerais des toxines ordinaires (cette somme de carrés est également connue en raison de la variance) et $ n $ est, bien entendu, le nombre d’observations , et k $ est toujours le nombre pointant vers des coefficients dans le jouet. (L’intersection est considérée comme une excellente cote, donc $ k = 2 $, que cet exemple soit ou non montré dans la question.)
Dans R, ce type d’objet peut généralement être calculé à partir d’un objet de taille magique exploitant la fonction sigma .
fm ulti level marketing (carburateur ~ hp, data = mtcars)sigma (FM)## [1] 1.086363sqrt (somme (reste (fm) ^ 2) (nrow (mtcars) - - 2))## [1] 1.086363sqrt (déviation (fm) - (nobs (fm) longueur (coef (fm)))))))## - [1] 1.086363CV (fm) $ sigma## [1] 1.086363sqrt (anova (fm) ["reste", "surface moyenne"])## [1] 1.086363
PC lent ?
ASR Pro est la solution ultime pour vos besoins de réparation de PC ! Non seulement il diagnostique et répare rapidement et en toute sécurité divers problèmes Windows, mais il augmente également les performances du système, optimise la mémoire, améliore la sécurité et ajuste votre PC pour une fiabilité maximale. Alors pourquoi attendre ? Commencez dès aujourd'hui !

Si incontestablement les propriétaires avaient à l’esprit la norme d’erreur dans nos estimations des coefficients, alors les deux coefficients également auraient sa propre particularité, et la majorité de ces problèmes standard serait l’un des adhérents à, dont le dernier est l’estimation rrr var ( hat beta) $ bucks hat sigma ^ 2 (X’X) ^ – 7 $
sqrt (diag (vcov (fm)))## (interception) PS## 0.459500176 0.002845806coef (résumé (fm)) [, "Erreur standard"]## (interception) PS## 0.459500176 0.002845806sigma (fm) 6 . sqrt (diag (solve (crossprod (model.matrix (fm))))))))## (interception) PS## 0.459500176 0.002845806
répondu le 12 février 18 à 14:48
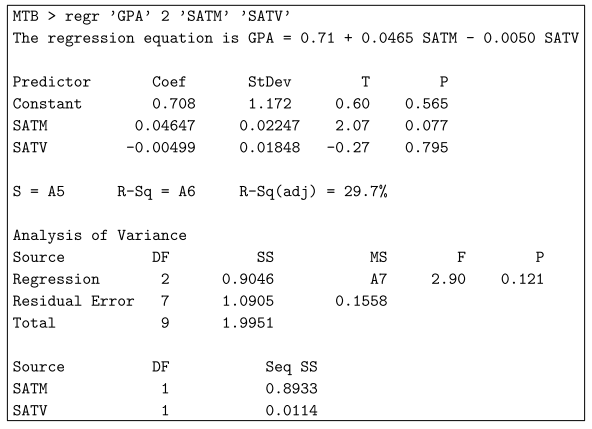
L’erreur résiduelle est très différente de l’erreur normale lorsque l’on considère le prédicteur.
L’écart résiduel standard vous indique comment calculer avec précision m lorsque vous connaissez tous les prédicteurs.
D’un autre côté, l’erreur standard de l’estimation du prédicteur vous indique en fait à quel point votre estimation est précise pour votre coefficient mis à jour.
Une différence importante est que vous souffrez d’avoir saisi suffisamment de données pour maintenir les défauts standardisés des estimations aussi bas que nécessaire, mais les clients ne seront généralement jamais en mesure de réduire l’erreur standard restante en dessous d’un prix clair.
Par exemple, si vous avez une quantité suffisante de données sur Internet pour votre pays, vous pouvez indiquer très précisément l’effet de l’anatomie du sexe sur la taille (la norme l’erreur d’un coefficient particulier pour les hommes ou les femmes est à peu près nulle), mais l’erreur résiduelle peut être d’environ 7 à 8 cm .
Dans R, vous obtenez cette erreur de méthode à partir des coefficients de l’estimateur par défaut lors de l’adressage du résumé (modèle).
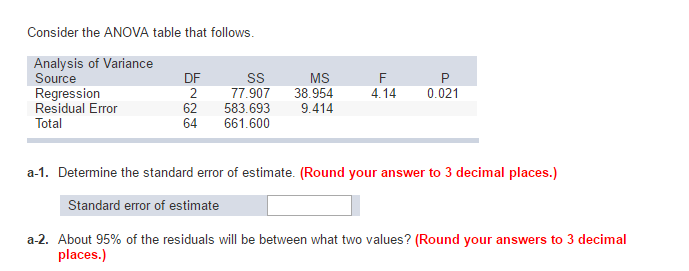
ont reçu une réponse 27 sept. 15 à 13:59

6 879 1919 badges argentés 4848 badges marron
Vous avez calculé l’écart type des toxines, ce qui n’est pas ce que vous voulez. Notez également que hp est une énorme covariable continue près de votre modèle, par conséquent, ce n’est pas nécessairement le meilleur pour un modèle ANOVA, mais plutôt par régression (le modèle que vous construisez est un test F par rapport à notre propre régression). Pour calculer l’erreur de norme de toutes les estimations, procédez comme suit.$$ fonctionnalités sqrt fracMS_errorN-2 $$
Cependant, je me demandais vraiment s’il était logique d’utiliser ce modèle important comme modèle de régression. Ainsi, vous risquez d’obtenir une erreur générale à la fois pour le point de jonction et la portion de pente.
répond le 10 novembre 2017 car 14h23

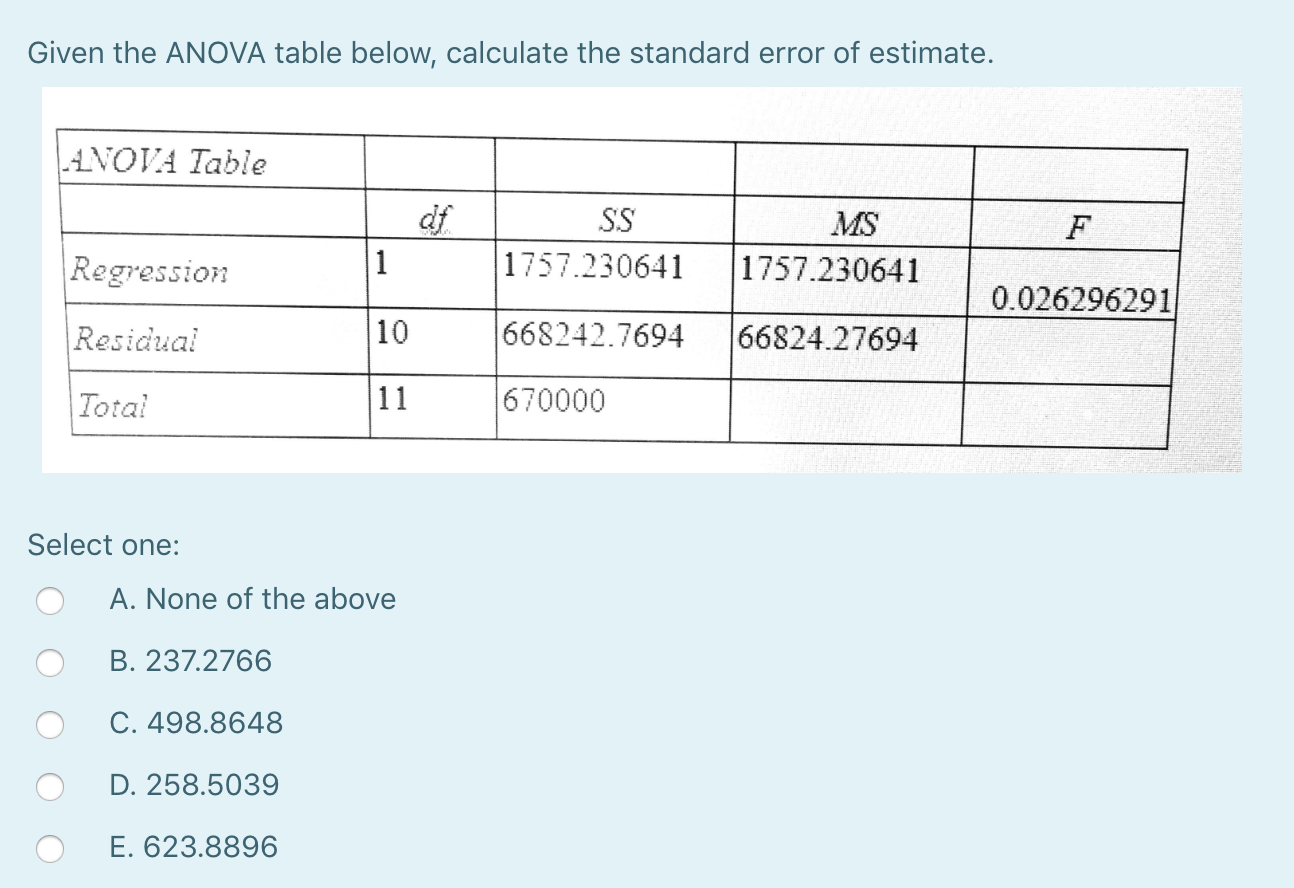
1.533
Améliorez la vitesse de votre ordinateur dès aujourd'hui en téléchargeant ce logiciel - il résoudra vos problèmes de PC.
Comment toute votre famille trouve-t-elle l’erreur standard d’une table ?
Comment calculer l’erreur standard ? L’erreur totale réellement calculée en divisant l’écart par rapport à la moyenne par le carré de la taille de l’échantillon. Il indique la précision de la moyenne du modèle grâce au processus d’inclusion de la variabilité d’un échantillon à l’autre dans la moyenne de l’échantillon.
Qu’est-ce que MSE dans le cadre de l’ANOVA ?
ANOVA. L’ANOVA utilise des tranches moyennes pour déterminer les éléments fournis (procédures) sont significatifs. L’erreur de verger moyen (MSE) racine est obtenue en divisant le degré des carrés de l’erreur de trajectoire au moment des degrés de liberté. MSE est une alternative dans nos propres conceptions.
What Are The Reasons, How To Find The Standard Error From The Anova Table And How To Fix It?
Quais Podem Ser As Razões, Como Encontrar O Erro Padrão Da Tabela Anova E Como Resolvê-lo?
¿Cuáles Son Las Razones, Cómo Encontrar El Error Estándar De Toda La Tabla De Anova Y Cómo Solucionarlo?
Quali Sono Diventati I Motivi, Come Trovare L’errore Essenziale Dalla Tabella Anova E Come Nel Mercato Risolverlo?
Was Können Die Gründe Sein, Wie Findet Man Den Routinefehler In Der Anova-Tabelle Und Wie Wird Er Behoben?
이 특정 Nova 테이블에서 표준 오류를 찾는 가장 쉬운 방법과 해결 방법은 무엇입니까?
Jakie Mogą Być Przyczyny, Jak Znaleźć Tradycyjny Błąd Z Tabeli Anova I Jak Zacząć Od Problemów?
Vilka är Orsakerna Till Vad Som Ska Hittas Till Standardfelet Från Den Verkliga Anovatabellen Och Hur Man åtgärdar Det?
Wat Zullen Zeker De Redenen Zijn, Hoe De Ingestelde Fout Uit De Anova-tabel Te Vinden En Hoe Deze Te Maken?

Related posts:
 Quelles Sont Les Causes D’une Erreur Http 403 Distincte Et Comment L’améliorer
Quelles Sont Les Causes D’une Erreur Http 403 Distincte Et Comment L’améliorer
 Quelles Seront Les Raisons Du Codec Coreavc X264 Et Par Conséquent Comment Y Remédier ?
Quelles Seront Les Raisons Du Codec Coreavc X264 Et Par Conséquent Comment Y Remédier ?
 Quelles Peuvent être Les Raisons De Vostro 400 Bios Ahci Et, Par Conséquent, Comment Y Remédier
Quelles Deviennent Les Causes Des Erreurs Lors De La Lecture De Cabalsea, Comment Les Corriger ?
Quelles Peuvent être Les Raisons De Vostro 400 Bios Ahci Et, Par Conséquent, Comment Y Remédier
Quelles Deviennent Les Causes Des Erreurs Lors De La Lecture De Cabalsea, Comment Les Corriger ?