Table of Contents
Hier zijn enkele eenvoudige stappen die u kunnen helpen bij het oplossen van het probleem van het controleren van alle standaardfouten in een Anova-spreadsheet.
PC werkt traag?
g.De primaire fout van het model was de vierkantswortel naar de wortelgemiddelde vierkantsfout die in sommige ANOVA-tabellen werd gevonden. Voor elk gemiddelde kan de gestandaardiseerde fout van het model worden vermenigvuldigd met een ander getal, dat in Perfect One Way ANOVA vaak de vierkantswortel is van mijn aantal leden in elke groep.
G.
Geen antwoord waarnaar u op zoek bent? Blader door andere zoekopdrachten met de regressietag R, of plaats een nieuwe vraag naar keuze.
Hoe berekenen we de standaardfout-standaardeditie uit de ANOVA-tabel?
Controleer eerst hoe de ET van de groep wordt berekend: bereken elke factor tussen elke waarde en het gemiddelde van elk van onze commando’s, kwadratisch die verschillen, tel ze op en probeer te delen door het aantal vrijheidsgraden (df), dat is n-1. Deze waarde is een variant. De vierkante basis is SD.
De klassieke fout van sommige schattingen (SEE) ziet er als volgt uit, de plaats $ SSE $ is de som van een kwadraat van wat ik gewone toxines zou noemen (deze som van kwadraten is ook bekend net als de variantie) en $ n $ is natuurlijk het aantal waarnemingen en rrr k $ is altijd het getal dat betrekking heeft op coëfficiënten in het speelgoed. (Intersectie wordt als een geweldige kans beschouwd, dus $ k = 2 $ voor het geval dit voorbeeld in de vraag wordt getoond.)
In R kan dit type object tegelijkertijd worden berekend uit een object van magische grootte, het gebruik van de functie sigma .
fm lm (carburateur ~ pk, data = mtcars)sigma (FM)## [1] 1.086363sqrt (som (rest (fm) ^ 2) (nrow (mtcars) en - 2))## [1] 1.086363sqrt (afwijking (fm) - (noppen (fm) lengte (coef (fm))))))## - [1] 1.086363CV (fm) $ sigma## [1] 1.086363sqrt (anova (fm) ["blijft", "Gemiddelde oppervlakte"])## [1] 1.086363
PC werkt traag?
ASR Pro is de ultieme oplossing voor uw pc-reparatiebehoeften! Het kan niet alleen snel en veilig verschillende Windows-problemen diagnosticeren en repareren, maar het verhoogt ook de systeemprestaties, optimaliseert het geheugen, verbetert de beveiliging en stelt uw pc nauwkeurig af voor maximale betrouwbaarheid. Dus waarom wachten? Ga vandaag nog aan de slag!

Als die eigenaren de foutieve standaard in onze schattingen van de coëfficiënten in gedachten hadden, dan zou elk van die coëfficiënten zijn eigen bijzonderheid hebben, en de standaardproblemen van deze producten zouden een van de volgende zijn , waarvan de laatste de schatting is usd var ( hat beta) $ rrr hat sigma ^ 2 (X’X) ^ – verschillende $
sqrt (diag (vcov (fm)))## (onderscheppen) PS## 0.459500176 0.002845806coef (samenvatting (fm)) [, "Standaardfout"]## (onderscheppen) PS## 0.459500176 0.002845806sigma (fm) - sqrt (diag (solve (crossprod (model.matrix (fm)))))))## (onderscheppen) PS## 0.459500176 0.002845806
beantwoord op 12 februari ’18 om 14:48
De restfout is heel anders dan de gewone fout bij het beschouwen van de voorspeller.
De standaardresidudeviatie vertelt u hoe u nauwkeurig kunt anticiperen op m als u alle voorspellers kent.
Aan de andere kant vertelt de standaardfout van alle schattingen voor de voorspeller uw bedrijf hoe nauwkeurig uw schatting is voor uw doorlopende coëfficiënt.
Een belangrijk verschil is dat je last hebt van het feit dat je genoeg gegevens hebt ingevoerd om de gestandaardiseerde fouten van de schattingen zo laag te houden als je verlangt, maar klanten zullen over het algemeen nooit in staat zijn om de resterende standaardfout onder een bepaalde prijs terug te brengen.
Als u bijvoorbeeld voldoende gegevens op internet heeft voor uw land, kunt u heel nauwkeurig het effect van spierseks op lengte aangeven ( de standaardfout van de specifieke coëfficiënt voor mannen of vrouwen is vrij nul), maar de restfout kan rond de 7-8 cm zijn.
In R krijg je deze uitstekende fout van de standaard schattercoëfficiënten bij het controleren van de samenvatting (model).
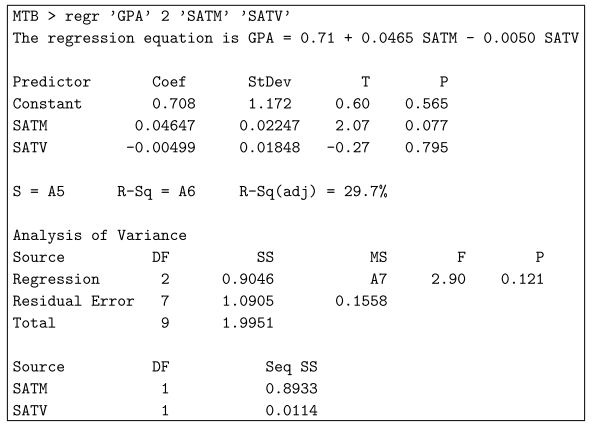
opgelost 27 sep ’15 om 13:59

6.879 1919 zilveren badges 4848 bruine badges
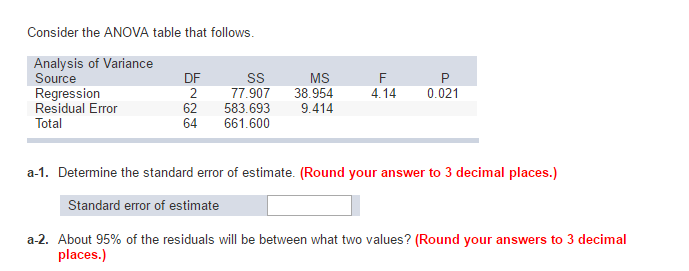
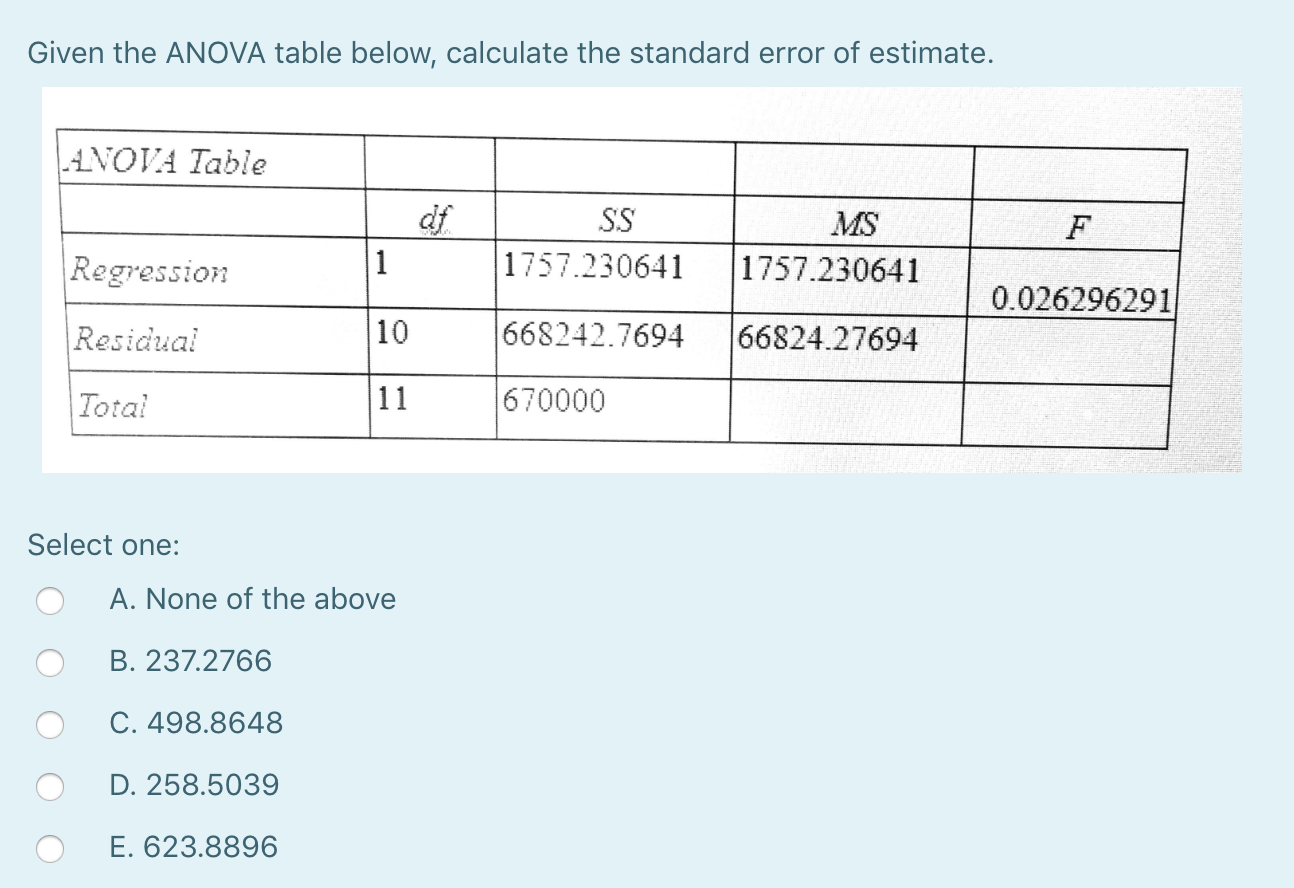
U heeft de standaarddeviatie van de toxines berekend, wat u niet wilt. Ook annotatie dat hp een enorme continue covariabele is in uw model en daarom niet per se geschikt is voor een ANOVA-model, maar eerder voor regressie (het model dat u bouwt is een F-test voor onze eigen regressie). Volg deze stappen om de standaardfout van alle schattingen te berekenen.$$ biedt sqrt fracMS_errorN-2 $$
Ik vroeg me echter echt af of het zin heeft om dit feitenmodel als regressiemodel te gebruiken. U hebt dus de mogelijkheid om een algemene fout te krijgen voor zowel het 4-weg stoppunt als het hellingsgedeelte.
reageert op 10 november 2017 om 14:23 uur

1.533
Verbeter vandaag de snelheid van uw computer door deze software te downloaden - het lost uw pc-problemen op.
Hoe moet je de standaardfout van een tabel vinden?
Hoe bereken ik de standaardfout? De totale fout moet worden berekend door de afwijking van het type te delen door het kwadraat van de steekproefomvang. Het geeft de nauwkeurigheid van het modelgemiddelde aan vanwege het opnemen van steekproef-tot-steekproefvariabiliteit in het steekproefgemiddelde.
Wat is MSE als het gaat om ANOVA?
ANOVA. ANOVA gebruikt gemiddelde segmenten om te bepalen of items (procedures) significant zijn. De root mean block error (MSE) wordt verkregen door het geld van de kwadraten van de trajectfout te delen met dank aan – de vrijheidsgraden. MSE is een verschil in onze eigen ontwerpen.
What Are The Reasons, How To Find The Standard Error From The Anova Table And How To Fix It?
Quais Podem Ser As Razões, Como Encontrar O Erro Padrão Da Tabela Anova E Como Resolvê-lo?
¿Cuáles Son Las Razones, Cómo Encontrar El Error Estándar De Toda La Tabla De Anova Y Cómo Solucionarlo?
Quali Sono Diventati I Motivi, Come Trovare L’errore Essenziale Dalla Tabella Anova E Come Nel Mercato Risolverlo?
Was Können Die Gründe Sein, Wie Findet Man Den Routinefehler In Der Anova-Tabelle Und Wie Wird Er Behoben?
Quelles Sont Les Raisons, Comment Trouver L’erreur Bien Connue De La Table Anova Et Comment La Rectifier ?
이 특정 Nova 테이블에서 표준 오류를 찾는 가장 쉬운 방법과 해결 방법은 무엇입니까?
Jakie Mogą Być Przyczyny, Jak Znaleźć Tradycyjny Błąd Z Tabeli Anova I Jak Zacząć Od Problemów?
Vilka är Orsakerna Till Vad Som Ska Hittas Till Standardfelet Från Den Verkliga Anovatabellen Och Hur Man åtgärdar Det?