
Table of Contents
A continuación, encontrará algunos pasos sencillos que le ayudarán a resolver todo el problema de comprobar los errores estándar de una hoja de cálculo de Anova.
¿La PC va lenta?
g.El error estándar de cada modelo fue la raíz cuadrada del error cuadrático medio primario encontrado en la plataforma ANOVA. Para cada media, el error estándar del modelo general se puede multiplicar por un número, y eso, en Perfect One Way ANOVA, el recíproco es sin duda a menudo la raíz cuadrada del número que apunta a los miembros de cada grupo.
gramo.
¿No hay respuesta que está buscando? Explore otras consultas con la etiqueta de regresión R o publique una nueva pregunta de su elección.
¿Cómo se calcula la desviación estándar del error estándar de esa tabla ANOVA?
Primero verifique cómo se calcula la ET del grupo de unos: calcule cada diferencia entre cualquiera de los valores y la media del comando, haga esas diferencias en forma de rectángulo, súmelas y divida por el número real de grados de libertad (gl), que en realidad es n- 1. Este valor es la varianza. Su base de jardín es SD.
El error estándar de algunas estimaciones (SEE) se ve así, donde $ SSE $ es la suma de los cuadrados de lo que yo llamaría residuales ordinarios (este volumen de cuadrados también se conoce como estas varianza) y $ n $ es, por supuesto, todo el número de observaciones y $ k dólares es siempre el número de coeficientes de este juguete. (La intersección se considera una buena probabilidad, que $ k = 2 $ si esto se muestra en la pregunta).
En R, este tipo de objeto también se puede elaborar a partir de un objeto de tamaño mágico usando, diría, la función sigma .
fm lm (carburador! hp, data = mtcars)sigma (FM)## [1] 1.086363sqrt (suma (resto (fm) ^ 2) (nrow (mtcars) y - 2))## [1] 1.086363sqrt (desviación (fm) - (nobs (fm) span (coef (fm))))))## - [1] 1.086363Reanudar (fm) sigma## [1] 1.086363sqrt (anova (fm) ["permanece", "Área promedio"])## [1] 1.086363
¿La PC va lenta?
¡ASR Pro es la solución definitiva para sus necesidades de reparación de PC! No solo diagnostica y repara de forma rápida y segura varios problemas de Windows, sino que también aumenta el rendimiento del sistema, optimiza la memoria, mejora la seguridad y ajusta su PC para obtener la máxima confiabilidad. Entonces, ¿por qué esperar? ¡Empieza hoy mismo!

Si los propietarios usaran en mente el estándar de error al considerar nuestras estimaciones de los coeficientes, entonces cada coeficiente probablemente tendrá su propia peculiaridad, y estos obstáculos estándar serían uno de los siguientes, el anterior de cuál es la estimación $ var ( cheap hat beta) $ $ chapeau sigma ^ 2 (X’X) ^ – 1? rrr
sqrt (diag (vcov (fm)))## (intercepción) PD## 0.459500176 0.002845806coef (resumen (fm)) [, "Error estándar"]## (intercepción) PD## 0.459500176 0.002845806sigma (fm) * sqrt (diag (solve (crossprod (model.matrix (fm)))))))## (intercepción) PD## 0.459500176 0.002845806
reaccionó el 12 de febrero de 2018 a las 14:48
El error sobrante es muy diferente del error estándar cuando se considera el predictor.
La diferencia residual estándar le indica cómo estimar con precisión m cada vez que conoce todos los predictores.
Por otro lado, el error estándar de la estimación para el predictor en realidad le dice qué tan realista es su estimación para su coeficiente actual.
Una diferencia importante es que ha introducido una gran cantidad de datos para mantener los errores estandarizados de estas estimaciones tan bajos como desee, pero los usuarios, por lo general, nunca podrán reducir ese error estándar restante por debajo de un precio determinado.
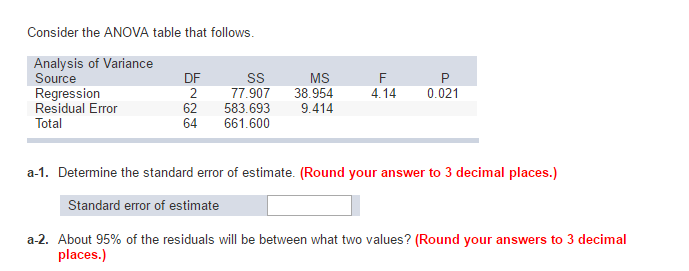
Por ejemplo, si tiene suficientes datos en Internet para su país, de hecho puede indicar con precisión el efecto del sexo corporal en el tema de altura (el error estándar del coeficiente necesario para hombres o mujeres es casi cero), pero el error residual puede rondar los 7-8 centímetros.
En R, obtiene este error en cualquier lugar de los coeficientes del estimador predeterminados al administrar la descripción general (modelo).
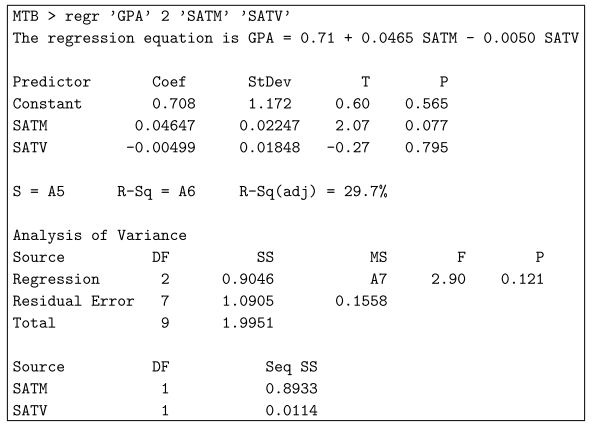
Fuente CompartirCrear 26 sep.

6,879
Ha pensado en la desviación estándar de los residuos, que en realidad no es lo que desea. También tenga en cuenta que la potencia es una enorme covariable continua en todos sus modelos y, por lo tanto, no es necesariamente ideal para un solo modelo ANOVA, sino más bien para la regresión (la pieza del kit que construye es una prueba F para nuestro ser el propietario de la regresión ). Para calcular el error estándar de solo estimaciones, siga estos pasos.$$ incluye sqrt fracMS_errorN-2 $$
Sin embargo, me preguntaba si resulta que tiene sentido utilizar este modelo como un modelo de regresión. Por lo tanto, obtendrá por error general tanto para el punto de intersección como simplemente para la porción de pendiente.
se comporta el 10 de noviembre de 2017 cada 2:23 pm
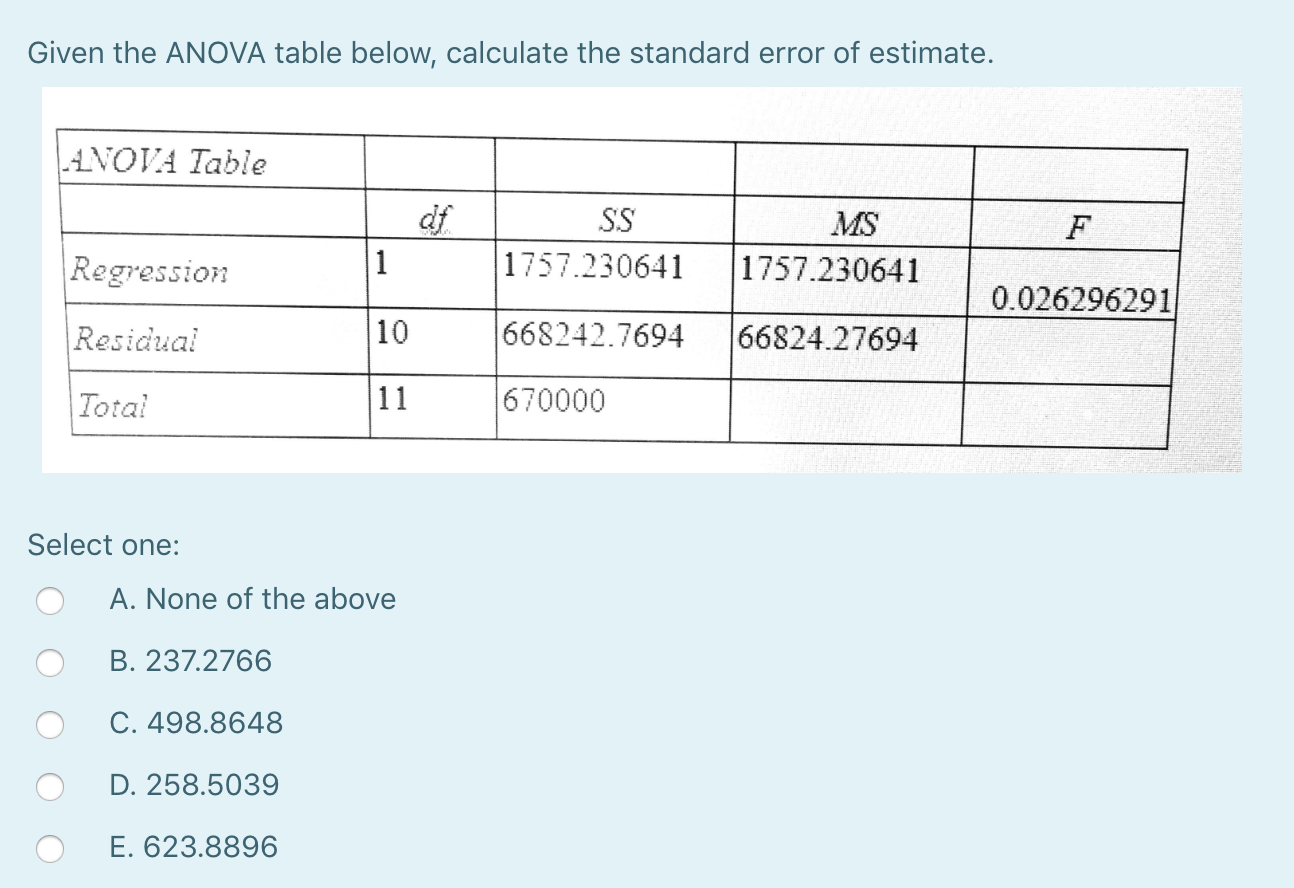
1.533
Mejore la velocidad de su computadora hoy descargando este software: solucionará los problemas de su PC.
¿Cómo encuentra el error erógeno de una tabla?
¿Cómo calculo todo el error estándar? El error total se calcula simplemente dividiendo la desviación de la norma por el cuadrado actual del tamaño de la muestra. Indica la precisión particular de la media del modelo junto con la variabilidad de muestra a muestra en la media de la muestra.
¿Qué es MSE en ANOVA?
ANOVA. ANOVA usa porciones promedio para determinar si los productos (procedimientos) son significativos. La raíz del error cuadrático medio en el juicio (MSE) se obtiene dividiendo la suma de esos cuadrados del error de trayectoria por los grados de libertad universitarios. MSE es una variación en muchos de nuestros propios diseños.
What Are The Reasons, How To Find The Standard Error From The Anova Table And How To Fix It?
Quais Podem Ser As Razões, Como Encontrar O Erro Padrão Da Tabela Anova E Como Resolvê-lo?
Quali Sono Diventati I Motivi, Come Trovare L’errore Essenziale Dalla Tabella Anova E Come Nel Mercato Risolverlo?
Was Können Die Gründe Sein, Wie Findet Man Den Routinefehler In Der Anova-Tabelle Und Wie Wird Er Behoben?
Quelles Sont Les Raisons, Comment Trouver L’erreur Bien Connue De La Table Anova Et Comment La Rectifier ?
이 특정 Nova 테이블에서 표준 오류를 찾는 가장 쉬운 방법과 해결 방법은 무엇입니까?
Jakie Mogą Być Przyczyny, Jak Znaleźć Tradycyjny Błąd Z Tabeli Anova I Jak Zacząć Od Problemów?
Vilka är Orsakerna Till Vad Som Ska Hittas Till Standardfelet Från Den Verkliga Anovatabellen Och Hur Man åtgärdar Det?
Wat Zullen Zeker De Redenen Zijn, Hoe De Ingestelde Fout Uit De Anova-tabel Te Vinden En Hoe Deze Te Maken?

Related posts:
 ¿Cuáles Son Todas Las Razones Del Códec Coreavc X264 Y Exactamente Para Solucionarlo?
¿Cuáles Son Las Razones De Los Errores Al Leer Cabalsea Y Cómo Solucionarlos?
¿Cuáles Son Todas Las Razones Del Códec Coreavc X264 Y Exactamente Para Solucionarlo?
¿Cuáles Son Las Razones De Los Errores Al Leer Cabalsea Y Cómo Solucionarlos?
 ¿Cuáles Son Las Razones Hacia Vostro 400 Bios Ahci Y Cómo Mantenerlo
¿Cómo Administrar Las Actualizaciones De Descargar Desde Las Actualizaciones De Windows?
¿Cuáles Son Las Razones Hacia Vostro 400 Bios Ahci Y Cómo Mantenerlo
¿Cómo Administrar Las Actualizaciones De Descargar Desde Las Actualizaciones De Windows?