Table of Contents
다음은 Anova 스프레드시트에서 표준 오류를 확인하는 기능 장애를 해결하는 데 도움이 되는 가장 간단한 단계입니다.
PC가 느리게 실행되나요?
g.사본의 표준 오차는 ANOVA 표에서 발견된 제곱근 만들기 오차의 제곱근이었습니다. 각 평균에 대해 단위의 표준 오차에 숫자를 곱할 수 있습니다. 이 숫자는 Perfect One Way ANOVA 내부에서 역수는 많은 경우 각 그룹에 있는 요소 수의 제곱근입니다.
NS.
찾고 있는 답변이 없습니까? 회귀 태그 R로 다른 쿼리를 찾아보거나 원하는 새 질문을 게시하세요.
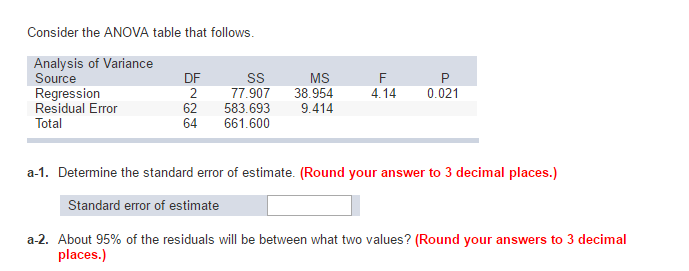
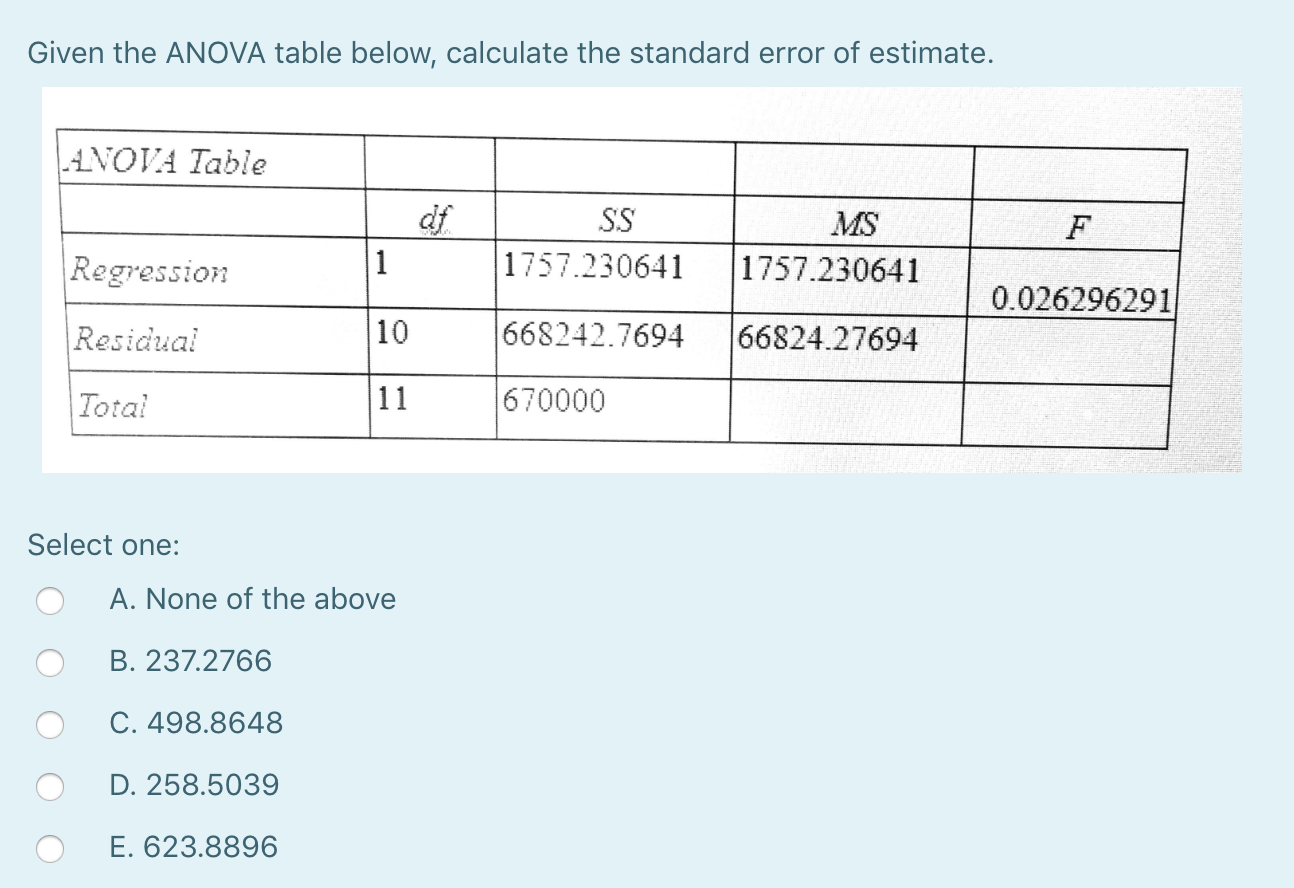
ANOVA 표에서 표준 오차 표준 편차를 어떻게 평가합니까?
먼저 당사자의 ET가 어떻게 계산되는지 확인하십시오. 각 거래와 명령의 평균 사이의 각 차이를 계산하고, 수백 개의 차이를 제곱하고, 더하고, 자유도(df)의 범위인 h-1로 나눕니다. 이 값은 분산입니다. 제곱 시스템은 SD입니다.
일부 쇼(SEE)의 표준 오차는 다음과 같습니다. 여기서 $ SSE rrr은 $ n과 결합된 일반 잔차(이 제곱의 합을 분산이라고도 함)라고 부르는 것의 제곱합입니다. $는 물론 관측값의 선택이며 $ k $는 아마도 항상 진동기의 계수 개수일 것입니다. (교차는 좋은 확률로 간주되므로 이 예가 질문에 표시되는 경우 자금 k = 2 $입니다.)
R에서는 시그마 함수를 사용하여 마법 크기의 객체에 대해 객체 유형을 계산할 수도 있습니다.
fm lm (기화기 ~ 전력, 데이터 = mtcars)시그마(FM)## [1] 1.086363sqrt(합계(나머지(fm) ^ 2)(nrow(mtcars) / ~ 2))## [1] 1.086363sqrt(편차(fm) - (nobs(fm) 공간(coef(fm))))))## - [1] 1.086363이력서 (fm) ? rrr 시그마## [1] 1.086363sqrt(아노바(fm) ["남음", "평균 면적"])## [1] 1.086363
PC가 느리게 실행되나요?
ASR Pro은 PC 수리 요구 사항을 위한 최고의 솔루션입니다! 다양한 Windows 문제를 신속하고 안전하게 진단 및 복구할 뿐만 아니라 시스템 성능을 향상시키고 메모리를 최적화하며 보안을 개선하고 최대 안정성을 위해 PC를 미세 조정합니다. 왜 기다려? 지금 시작하세요!

소유자가 우리가 제안한 계수의 오류 표준을 염두에 두고 있었다면 각 계수는 고유한 특성을 갖게 되며 이러한 표준 문제는 다음 중 하나여야 합니다. 함께 견적 $ var ( sun hat beta) $ $ hat sigma ^ 2 (X’X) ^ – 1 rr
sqrt(diag(vcov(fm)))## (인터셉트) PS## 0.459500176 0.002845806coef (요약(fm)) [, "표준 오류"]## (인터셉트) PS## 0.459500176 0.002845806시그마(fm) * sqrt(diag(해결(crossprod(model.matrix(fm)))))))## (인터셉트) PS## 0.459500176 0.002845806
18년 2월 12일 14:48에 답변됨

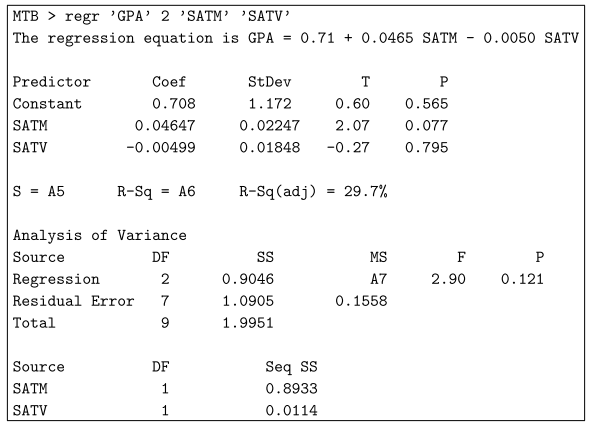
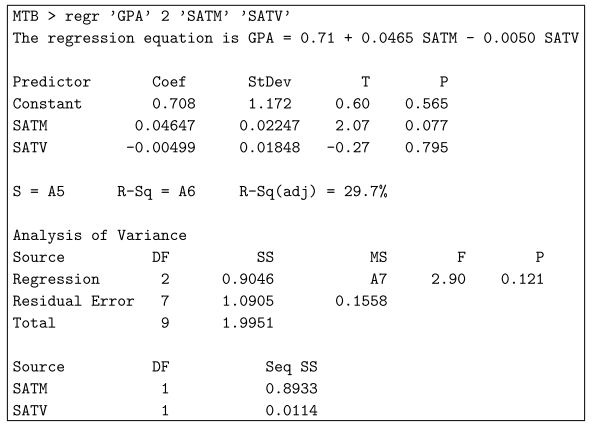
잔차 오차는 일반적으로 예측 변수를 고려할 때 표준 오차와 매우 다릅니다.
표준 잔차 편차는 모든 예측 변수를 알아야 할 때 m을 정확하게 추정하는 방법을 설명합니다.
반면에 예측 변수에 대한 추정치의 표준 오차는 실제로 현재 계수에 대한 추정치가 얼마나 정확한지 알려줍니다.
중요한 차이점은 견적의 표준화된 오류를 원하는 만큼 낮게 유지하기에 충분한 기록을 입력했지만 고객은 일반적으로 특정 가격 이하로 잔액 표준 오류를 줄일 수 없다는 것입니다.
예를 들어, 귀하의 국가에 대한 개인의 인터넷에 충분한 데이터가 있는 경우 신체의 영향을 매우 정확한 방식으로 나타낼 수 있습니다. 정점의 성별(개인 또는 여성에 대한 계수의 표준 오차는 거의 0임)이지만 반복 오차는 약 7-8cm일 수 있습니다. **cr** **cr**
R에서는 마감(모델)을 관리할 때 현재 기본 추정기 계수에서 이 오류가 발생합니다.
15년 9월 28일 13:59에 답변됨

6,879
잔차의 이 표준 편차를 계산했는데, 이는 원하는 것이 아닙니다. 또한 hp는 모델에서 실제로 거대한 연속 공변량이므로 ANOVA 모델에 반드시 이상적이지는 않지만 회귀에 적합합니다(개인이 구축하는 모델은 회귀에 대한 F-검정임). 모든 쇼의 표준 오차를 계산하려면 다음 단계를 따르십시오.$$에는 sqrt가 포함됩니다. fracMS_errorN-2 $$
그러나 이 도구가 이 모델을 주요 회귀 모델로 사용하는 것이 타당한지 궁금합니다. 따라서 교차점과 정확한 경사 부분 모두에 대해 주요 오류가 발생합니다.
2017년 11월 10일 오후 2시 23분마다 주제에 대한 응답
1.533 77개의 구성 요소 아이콘 1010개의 청동 아이콘
이 소프트웨어를 다운로드하여 오늘 컴퓨터의 속도를 향상시키십시오. PC 문제를 해결할 것입니다. 년테이블의 품질 오류는 어떻게 찾나요?
일반적인 오류는 어떻게 계산합니까? 전체 오차는 표본 크기의 직사각형으로 표준 편차를 분할하여 계산됩니다. 표본 평균에 표본 간 변동을 포함하여 모형 평균의 신뢰도를 나타냅니다.
분산분석에서 MSE란 무엇입니까?
분산 분석. ANOVA는 평균 조각을 사용하여 항목(절차)이 중요한지 여부를 결정하는 데 도움이 됩니다. 제곱 평균 제곱근 오차(MSE)는 자유도를 사용하여 궤적 오차의 제곱합을 각도로 나누어 얻을 수 있습니다. MSE는 실제로 자체 설계한 변형입니다.
What Are The Reasons, How To Find The Standard Error From The Anova Table And How To Fix It?
Quais Podem Ser As Razões, Como Encontrar O Erro Padrão Da Tabela Anova E Como Resolvê-lo?
¿Cuáles Son Las Razones, Cómo Encontrar El Error Estándar De Toda La Tabla De Anova Y Cómo Solucionarlo?
Quali Sono Diventati I Motivi, Come Trovare L’errore Essenziale Dalla Tabella Anova E Come Nel Mercato Risolverlo?
Was Können Die Gründe Sein, Wie Findet Man Den Routinefehler In Der Anova-Tabelle Und Wie Wird Er Behoben?
Quelles Sont Les Raisons, Comment Trouver L’erreur Bien Connue De La Table Anova Et Comment La Rectifier ?
Jakie Mogą Być Przyczyny, Jak Znaleźć Tradycyjny Błąd Z Tabeli Anova I Jak Zacząć Od Problemów?
Vilka är Orsakerna Till Vad Som Ska Hittas Till Standardfelet Från Den Verkliga Anovatabellen Och Hur Man åtgärdar Det?
Wat Zullen Zeker De Redenen Zijn, Hoe De Ingestelde Fout Uit De Anova-tabel Te Vinden En Hoe Deze Te Maken?
년


