Table of Contents
Datorn går långsamt?
I den här guiden kommer vi att analysera några potentiella orsaker som kan påverka standarddelen av provfördelningen av provfördelningen, utöver det kommer jag att föreslå några möjliga korrigeringar av det faktum att du kan försöka lösa det här problemet.Standardhantering (SE) förknippad med provandel: √ (p (1-p) n). Obs: Standardfelet kommer vanligtvis att minska med ökande urvalsstorlek.
- Beteende när det gäller förhållandet till provets proportioner.
- Ungefärlig fördelning av provandelen.
CO-6. Tillämpa de grundläggande begreppen sannolikhet, chans Varians och vanliga statistiska sannolikhetsfördelningar.
Proportioner av beteendemönster
EU 6.21: Använd provproportion när du väljer delning (om tillämpligt). I synnerhet måste du vara helt redo att identifiera exceptionella exemplar från en specifik gen.
- Den oväntade fördelningen av proportioner som liknar prov (p-hat) till dubbla prover (av exakt storlek) kallas marknadsförings-p-hat-prov.
Målet med följande videoövning är verkligen att säkerställa att information om centrum, tjänst och form av provfördelningen kommer via p-hatten genom rekonstruktionssimuleringar.
Vid denna metodpunkt har vi en bra idé om vad som händer när vi bekräftar slumpmässiga urval från vår population. Vår simulator antar att vår första misstänkta om din nuvarande form och mittpunkt av mönstret är korrekt. Om det finns en mycket stor andel p i den allmänna befolkningen, ja då har slumpmässiga urval av samma typ från ens allmänna population också proportionerna av själva urvalet p. Vad som är ännu farligare är det faktum att den selektiva fördelningen av proportioner har en genomsnittlig respekt för p.
Vi har också hittat goda skäl i den här situationen att proportionerna för de fria mallarna är ungefär normala. Vi får se senare var detta inte alltid är fallet. Men visst är urvalets proportioner fördelade såklart, en del av fördelningen är koncentrerad till q.
Vi vill nu att du ska ha möjlighet att använda simulering för att hjälpa oss tänka på den förväntade variationen i urvalsförhållanden. Våra rovinstinkter säger oss att större urval täcker medborgarna ungefär bättre, så vi kan förvänta oss ännu inte fullt så variationer med större urval.
Datorn går långsamt?
ASR Pro är den ultimata lösningen för dina PC-reparationsbehov! Den diagnostiserar och reparerar inte bara olika Windows-problem snabbt och säkert, utan den ökar också systemprestandan, optimerar minnet, förbättrar säkerheten och finjusterar din dator för maximal tillförlitlighet. Så varför vänta? Kom igång idag!

I nästa körning kommer vi vanligtvis att använda simulering för att diskutera denna viktiga idé. Efter detta avsnitt kommer vi definitivt att koppla dessa idéer till en mer formell process.
Förstärkta modeller är lämpliga för vår information. Större slumpmässiga urval ger en bättre strategi för din andel av befolkningen. Om huvudurvalet nu är stort, minskar proportionerna av hur urvalet kommer till p. Med andra ord, med större urval är fördelningen av prover normalt mindre flyktig. Avancerad sannolikhetsteori bekräftar våra studier och fördelar. ger ett mycket mer rätt sätt att beskriva den aktuella förändringen i styckförhållande. Detta beskrivs nedan.
Selektiv proportion relaterad till distribution
Hur får man standardfelet i samplingsfördelningen?
För att ta genomsnittet av en mängd information, inget annat än att lägga ihop alla värden i den marknadsföringsinformationen och dividera med antalet datapunkter.För att hitta kvalitetsfelet, ta standardskillnaden för en större del av en uppsättning på grund av prover och dividera sedan med kvadraten på den storlek du väljer.
Om upprepade specialprover dras för en kategorisk variabel med hjälp av en given variabel n från ett verkligt värdesamhälle där exakt andelen i din observationskategori är p, då är medelvärdet inklusive alla urvalsdimensioner (p -hat) är andelen av befolkningen (p).
När det gäller frakten av alla uppsättningar av sampel, kräver teorin beteendet hos en mycket mer exakt för att kunna säga att för stora sampel är den exakta multiplikationen mindre. Faktum är att referensavvikelsen avseende provproportioner är direkt relaterad till provkvantitet, som klassificeras nedan.
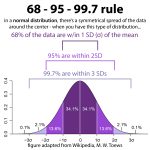
Eftersom urvalsstorleken n är relaterad till kvadratroten för nämnaren, minskar standardavvikelsen som du ser, urvalsstorleken ökar. Slutligen förblir den exakta formen bland p-hatfördelningen ungefär normal så utdragen eftersom storleken på n-testet är tillräckligt stor. Enligt konventionen måste np och n (1 – p) vara minst 10.
Låt oss tillämpa detta resultat på var och en. Se nästa scenario och se hur det kan jämföras med vår sim.
I vårt exempel är n = 5 storlek) (prov och p = 0,6. Anmärkning angående np = 8 10 p) och n (1 är lika med tio ¥ 10. Sålunda kan vi sluta oss till faktum p- hatten kommer att handla om nivån av skicklighet för normalfördelningen med ett medelvärde = 0,6 standard och avvikelse
(vilket alltid är väldigt likt det vi såg i den bästa simuleringen).
- Dessa goda resultat liknar de för de kända binomialvariablerna (X) som anges ovan. Var noga med att inte blanda ihop resultaten och den genomsnittliga standardavvikelsen för X på grund av p-hat-personer.
När vi bildar ett urval av fördelningen kan vi vanligtvis tillämpa standardavvikelsens värde och använda z-poäng för att beskriva sannolikheter. Låt oss ta en titt på några exempel.
För att undersöka effekten av urvalsstorleken på hela sannolikheten för dessa beräkningar, överväg följande ändring av vårt exempel.
- Så länge som hela försöket verkligen är slumpmässigt, borde p-hat-fördelningen beskrivas som centrerad på p, oavsett storleken på experimentet. Större o Prover har inte fått så bred spridning. I respektive fall, om vi multiplicerar strukturstorleken med 23 och ökar den från 150 till 2500, hur standardavvikelsen minskar till 1/5 av den initiala standardmodifieringen. Urvalsandelen avviker mindre orsakad från populationsandelen noll. Om 6, så är ditt urval större: det tenderar att minska från 0,5 till 0,7 för prover av storleksantal och tenderar att minska mellan 0,58 utöver det 0,62 för prover av storlek 2500. Detta betyder långt ifrån att det sanna värdet är helt enkelt bara 0,56 för 100 relaterade sampel (större än 20 % sannolikhet), men det är nästan omöjligt att ange ett lämpligt värde på bara 0. För sextio ut på grund av 2500 sampel (nästan noll sannolikhet).
EXEMPEL 6: Beteende hos aspektmönster
Ungefär 60 % av deltidsstudenterna i USA tenderar att vara kvinnor. Övrigt (uttryckt i nyckelord och fraser är andelen kvinnor bland deltidsstuderande alltid p = 0,6). Vad kan förväntas medan termer av beteendet hos varje andel kopplad till kvinnor i urvalet (p-hat) om det ändamålsenliga urvalet, urvalsstorlek 100 är långt ifrån specifika populationen av alla deltidsanställda högskole- eller universitetspersoner i kursen En dag ?
Som vi såg tidigare, främst på grund av urvalsvariation, antar urvalsandelen i icke-linjära urval av storlek 100 en numerisk moral som kan variera enligt lagarna mellan slumpmässighet: med andra ord, urvalsandelen är bokstavligen godtyckligt stor. För att sammanfatta beteendet hos en ny obunden variabel, låt oss fokusera på tre egenskaper som är jämförbara med dess fördelning: centrum, allmän spridning och utseende.

Medium: Vissa prover är i den låga nivån, typer av som 0,55 eller 0,58, medan andra är nära den översta, som 0,61 eller 0,66. Det är rimligt att förvänta sig att var och en av de viktigaste proportionerna i urvalet kommer att ha ett genomsnitt över dessa basfraktioner av talet 0 i varje upprepat slumpmässigt urval. 6. Med andra ord bör den huvudsakliga obligatoriska hänvisningen till p-hat-fördelningen verkligen vara p.
Fördelning: för produkter av ett hundratal eller så förväntar vi oss att urvalsfrekvensen för en kvinna inte kommer att skilja sig signifikant från populationsupplysningen på 0,6 samtidigt. Provintervall mindre än 0,5 eller större än 0,7 skulle med största sannolikhet vara ganska oväntat. Å andra sidan, inom den tar vi bara en maträtt i storlek tio, kommer vi inte automatiskt att bli förvånade även om vi använder detta ett litet urval av damer, främst för att 4/1 0 = 0,4, sortera tillsammans med eller bättre, även om 8/ 10 = 0,8. Därför spelar dessa provstorlekar en roll för den stora skillnaden i reproduktionen av provandelen: för stora produkter bör det vara mindre varians, för mindre bitar bör det vara mer varians.
Form: Provproportioner nära 0,6 borde förmodligen vara det vanligaste, och provproportioner långt över 0,6 i båda riktningarna kommer säkerligen att bli allt mindre sannolika. Med andra ord, formen på kvinnans fördelning ska bukta ut i mitten samt smälta samman i ändarna: den ska på någon nivå bli normal.
EXEMPEL 7: Använda ett distributionsmönster som pekar på P-hat
Ett stickprov på 100 studenter drogs från majoriteten av deltidsstudenter i USA, där andelen kvinnor generellt är 0,6.
(a) Mellan vilket värdepar (p-hat) finns det en stor 95% chans att andelen erfarenhet förmodligen kommer att vara?
Först av allt, lägg märke till att en viss p-hat-fördelning är komplett med medelvärde p = 0,6, standardavvikelse
och formen din familj kan kalla normal, 100 (0, eftersom np =. är lika med 6) 59 och n (1 – p) är lika med 100 (0.4) = Om 58 är båda betydligt bättre än 10 Standardavvikelsen regel är sanningen: sannolikheten i förhållande till 0,95 addition att p-hat faktiskt är inom 2 standardavvikelser beror på signifikansen som, det vill säga mellan 0,6–2 (0,05) och 0,6 + till (0,05). Sannolikheten för att p-hatten sedan kommer att falla är cirka 95 % med samplingstidsramen (0,5, 0,7) i denna storleksriktlinje.
(b) Vad är sannolikheten att andelen tillsammans med provets p-hat är mindre än eller medelvärde till 0,56?
Vi kommer att normalisera 0,56 mot din Z-poäng genom att subtrahera medelvärdet och dela den högsta poängen med standardavvikelsen. Vi kan sedan bestämma sannolikheten med hjälp av någon sorts erogen hastighetskalkylator eller tabell. 8: C
Provfördelning av ett prov associerat med P-hat

Våra deltidsstudenter från större delen av USA valdes slumpmässigt ut bland 2 500 studenter, med någon form av en total kvinnlig andel på 0,6.
(a) Det finns alltid en 95% chans att summan av urvalet (p-hat) ligger mellan vilka synpunkter?
Den första tonen för vilken fördelningen har ett medelvärde p = 0,6, kompenserar
och vanligtvis en form som närmar sig utbredd, eftersom np = 2500 (0,6) = Et nord (1 femton cent – p) = tvåtusenfemhundra (0,4) = 1000 båda är mycket större än tio. Korrelerad standardavvikelseregel: sannolikheten att p-hat är definitivt inom 2 standardavvikelser från ingången, faktum är, H. mellan 0,6-2 (0,01) och 0,6 + steg 2 (0,01). Sannolikheten att p-hatten utan tvekan kommer att förekomma i alla urval (intervall 0 58, 0,62) som för denna storlek är i sin tur med 95%.
(b) Vad är sannolikheten att en majoritet av urvalet för p-hat-testet till och med är mindre än eller lika med 0,56?
Vilket är standardfelet bland urvalsfördelningen av urvalets medelvärde?
Standardfel råkar vara helt enkelt en statistisk term som mäter var och en av vår precision med vilken en provfördelning representerar en viss konfidenspopulation med standardavvikelsen. I bet avviker urvalets medelvärde från det slutliga mänskliga populationsmedelvärdet; denna avvikelse är faktiskt medelvärdets normfel.
Vi normaliserar 0,56 till endast genom att subtrahera medelvärdet och dividera måltiderna med standardavvikelsen. Då kommer vi sannolikt ganska många att hitta sannolikheten med en bil eller ibland en normal normal tabell.
Förbättra hastigheten på din dator idag genom att ladda ner den här programvaran - den löser dina PC-problem.Correction Of The Sample Rate Of The Sample Distribution With Standard Errors
Korekta Częstotliwości Próbkowania W Stosunku Do Rozkładu Próby Z Błędami Standardowymi
Correção Da Taxa De Ajuste Da Distribuição Da Amostra Com Erros Clássicos
Correzione Del Track Rate Della Distribuzione Del Campione Con Errori Impostati
Correctie Met Betrekking Tot De Steekproeffrequentie Van De Voorbeeldinzendingen Met Standaardfouten
Corrección Del Precio De Venta De Muestra De La Distribución De Muestra Con Errores Estándar
Correction Du Taux De Groupe De La Distribution De L’échantillon Avec Des Erreurs Familières
Корректировка выборочной потребности выборочного распределения со стандартными ошибками
Korrektur Der Samplerate In Verbindung Mit Der Sampleverteilung Mit Standardfehlern
광범위한 오류가 있는 표본 분포의 표본 비율 수정