Table of Contents
PC가 느리게 실행되나요?
시스템에 널리 사용되는 오류 추적 기능이 있는 경우 이 블로그 기록이 도움이 될 수 있습니다.ncss.com 이미지: ncss.com 일반적으로 표준편차(SD) 그래프를 그리려면 geom_errorbar()를 사용해야 합니다. 우선, 다른 데이터 세트를 생성할 수 있는데, 이는 연속 오류를 생성하는 데 가장 시간이 많이 소요되는 방법입니다. 요즘에는 표준 오차(표준 편차를 N의 주 원인 제곱으로 나눈 값)도 추정합니다.
이전 기사에서 PROC SGPLOT의 VLINE 문은 주어진 시간에 평범한 응답을 찾는 쉬운 방법이라고 언급했습니다. 나는 이미 “오차 막대”의 크기에 대해 세 가지 옵션을 선택해야 한다고 선언했습니다.데이터의 큰 차이에 대한 표준, 내 평균의 표준 오류 또는 개인 평균에 대한 신뢰 길이.이것은 여러 옵션을 비교하여 기사를 설명합니다. 새로운 것 어떤 것을 선택하느냐는 놀라운 청중에게 어떤 종류의 정보를 전달하고 싶은지에 달려 있습니다. 내가 보여주겠지만, 일부 통계는 다른 통계보다 해독하기가 정말 쉽습니다. 그런 기사의 마지막에서 내가 추천하는 통계가 무엇인지 알려 드리겠습니다.
샘플 데이터
다음 단계인 DATA는 여러 특정 시점의 프롬프트를 시뮬레이션합니다. 임의의 시간에 발견된 데이터는 일반적으로 문서의 표시, 표준 편차 및 표본 크기가 매번 변경되지만 곱해집니다.
상자 이야기는 각 시간 단계에서만 데이터의 분포를 개략적으로 보여줍니다. 사각형은 데이터 분포를 나타내기 위해 일부 사분위수 범위와 수염을 사용합니다. 라인은 항상 답변 작업을 통해 리소스를 연결합니다.
빈 차트는 정확한 정보가 없는 실제 대상 고객 내에서 적절하지 않을 수 있습니다. 간단히 말해서 어떤 종류의 광고도 정보의 변화를 보여주는 귀중한 시간과 오류의 각 지점에 대한 카페 그래프입니다. 그러나 오차 막대의 높이를 표시하려면 어떤 통계를 사용해야 할까요? 좋은 답변의 변형을 확인하는 가장 좋은 방법은 무엇입니까?
표준 편차, SEM 및 CLM 간의 관계
오차 밴드와의 조합이 구성되고 해석되는 방법을 제안하기 전에 이 관계는 표본 표준 편차, 표준 오차와 연결된 유형(SEM) 사이에 의심의 여지가 없다는 점을 다시 강조하고 싶습니다. (절반) 너비 CLM(신뢰 위상 평균). 이러한 통계와 유사한 모든 것은 맛 평균 편차(SD)를 기반으로 하는 것으로 보입니다. SEM 및 CLM 너비는 실제로 일반적으로 분산의 배수이며, 승수가 그룹 크기에 따라 달라질 수 있다는 패러다임입니다.
<울>
PROC MEANS와 DATA 짧은 단계를 사용하여 이 세 가지 통계와 더 많은 통계가 어떻게 관련되어 있는지 보여주는 특정 관련 통계를 중단할 수 있습니다.
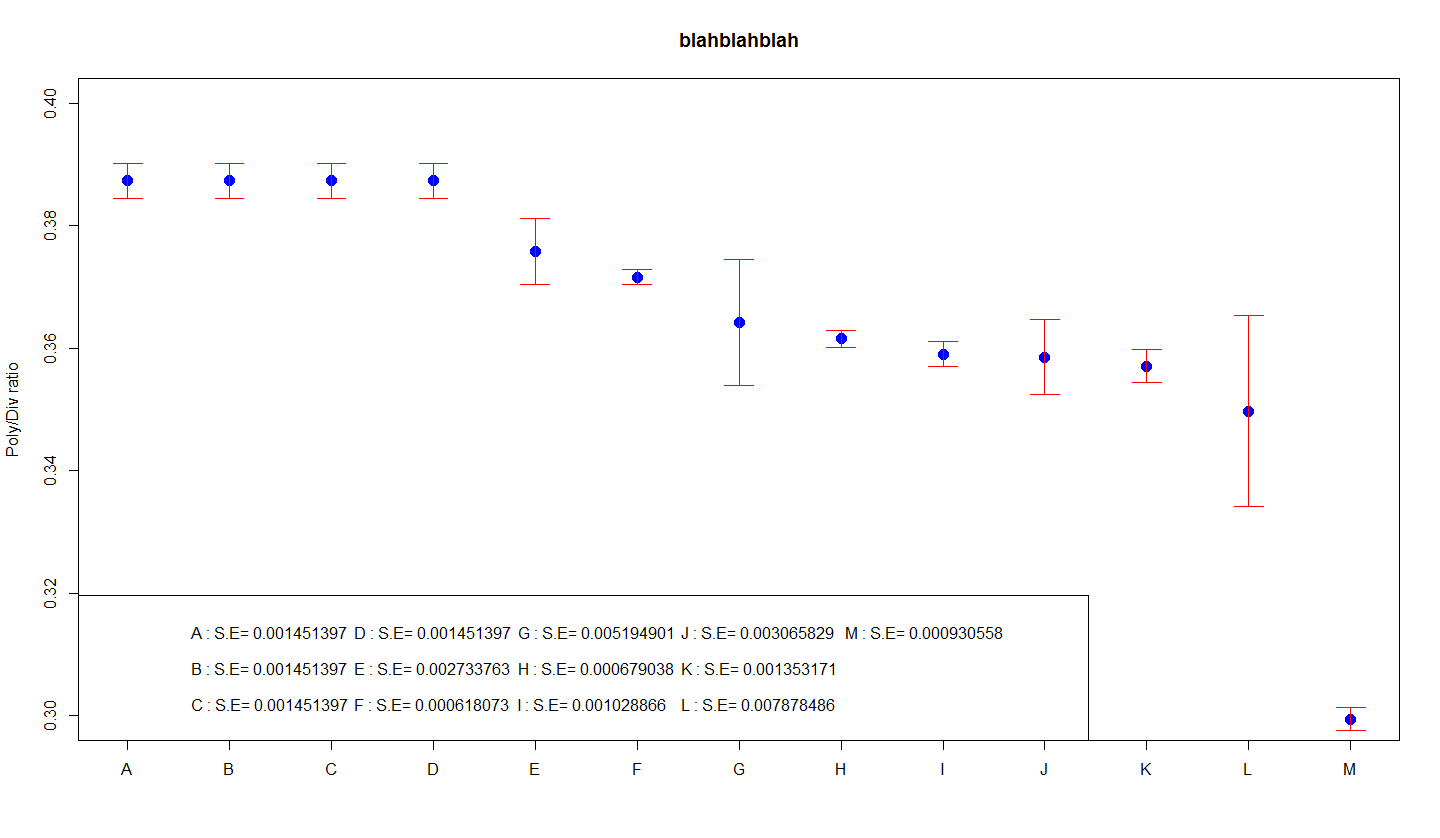
표는 시점당 모든 정규 편차(SD)와 표본 크기(N)를 보여줍니다. SEM 열은 sqrt(N)와 비교할 때 SD입니다. CLMWidth 값은 SEM 값의 두 배보다 약간 더 큽니다. (관심은 N입니다. 이 연구의 경우 2.03에서 2.06 사이입니다.)
개인 오차 막대에 대해 계산한 품질 편차(또는 표준 오차) 신념을 사용하려면 오차 금액 아래에서 각 사용자 정의 옵션을 선택하고 일반적으로 값 지정 버튼을 클릭합니다. 그러면 개인에게 이 오차 막대의 값을 입력하도록 요청하는 작은 사용자 정의 오차 막대 대화 상자가 나타납니다.
다음 섹션에서 볼 수 있듯이 값은SD, SEM 및 CLMWidth 열은 오류의 정도, STDDEV, STDERR 및 CLM 소스 이전에 재생할 때 열(각각) 현재 LIMITSTAT = PROC SGPLOT일 때 VLINE 문의 매개변수입니다.
선택한 오류 표시줄 보기 및 해석
표준 오차를 어떻게 그래프로 나타낼 수 있습니까?
표준 오차는 표준 편차를 옵션 평균의 제곱 코어로 나누어 계산했습니다(N은 종종 지원되는 것으로 간주됨). 이 경우 5개의 숫자가 만들어졌으므로(N = 5) 표준판은 의심할 여지 없이 5와 관련된 제곱근으로 나눌 수 있습니다.
여러 개의 오차 막대를 모두 정확히 같은 척도로 그린 다음 각 그래프를 인식하는 방법에 대해 논의해 보겠습니다.일부 해석에서는 정규 분포 데이터와 관련된 68-95-99.7 규칙을 사용합니다.다음 제안은 오차 막대가 있는 3개의 장소 플롯을 생성합니다.
이러한 특수 오류 막대에서 표준 편차 사용
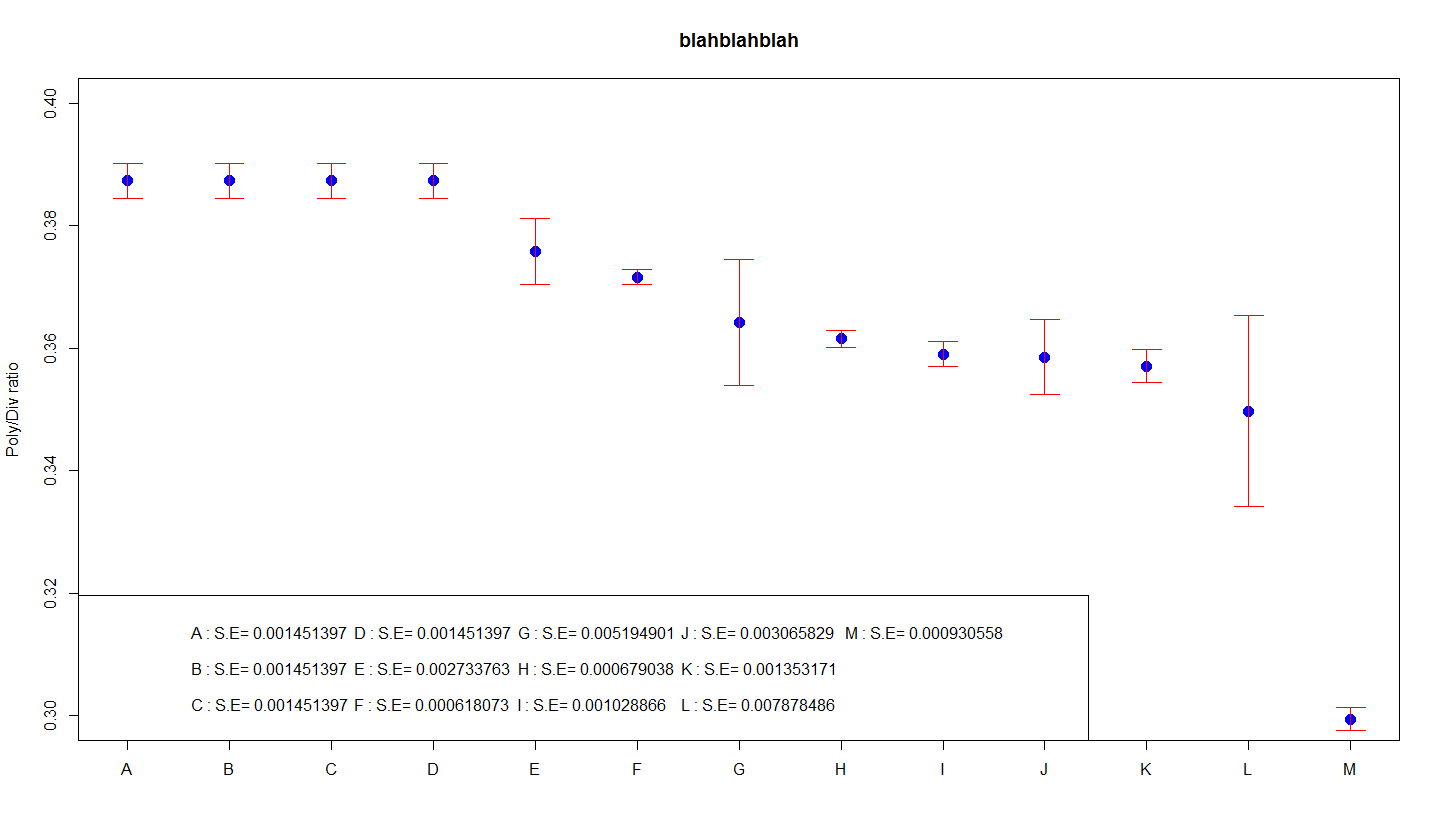
첫 번째 그래프에서 오류 청크의 기본 길이는 항상 출력 값에 해당합니다. 이는 표준 변경이 결과와 직접 관련되기 때문에 그래픽으로 설명하는 것이 더 쉬울 것입니다. 표준 대안은 콘텐츠의 변동을 측정한 것입니다. 이 데이터가 항상 자연스럽게 분포되어 있다면, 그 시점에서 (1) 데이터의 약 64%가 오차 막대를 포함하여 범위에서 인식하고, 그러면 (2) 데이터는 실제로 데이터의 3배의 달성 크기입니다. 오차 막대.
오차 막대와 관련하여 일반적인 편차를 활용하십시오. 첫 번째 그래프에서 주요 오차 막대와 관련된 길이는 주어진 시간의 표준 차이를 나타냅니다. 표준 편차는 일반적으로 데이터와 확실히 관련이 있기 때문에 설명하기가 가장 쉽습니다. 주요 격차는 의심할 여지 없이 데이터 불평등의 척도입니다.
이 그래프의 주요 이점은 기본적으로 일반 사용자에게 친숙한 용어인 “표준 편차”라는 것입니다. 단점은 그래프에 평균화의 모든 세부 사항이 표시되지 않는다는 것입니다. 원하는 것을 위해서는 몇 가지 다른 훌륭한 특성 중 하나가 필요합니다.
오류 라운지에 기본 여백 사용
PC가 느리게 실행되나요?
ASR Pro은 PC 수리 요구 사항을 위한 최고의 솔루션입니다! 다양한 Windows 문제를 신속하고 안전하게 진단 및 복구할 뿐만 아니라 시스템 성능을 향상시키고 메모리를 최적화하며 보안을 개선하고 최대 안정성을 위해 PC를 미세 조정합니다. 왜 기다려? 지금 시작하세요!

두 번째 그래프에서 모든 오차 막대의 길이는 실제 평균(SEM)의 표준 오차입니다.전문가가 아닌 청중의 경우 이는 정확한 추론이기 때문에 입증하기가 훨씬 더 어렵습니다.정성적 설명 판단은 SEM이 평균에 비해 정확도를 보여야 한다는 것입니다. 소형은 대형 SEM보다 정확도가 매우 높음을 의미합니다.
정량적 연구는 “통계와 관련된 무작위 분포” 및 “반복 실험”과 같은 고급 개념의 사용이 필요합니다. 모든 SEM 문서에 대해 현재 평균인 표본 분포의 표준 편차 추정값입니다. 평균 샘플에 대한 일일 금융 서비스는 모집단의 많은 부분에 대해 무작위 샘플을 반복적으로 샘플링하고 각 샘플에 대한 평균을 계산함으로써 이해될 것임을 기억하십시오. 규범은 단순히 표본 평균을 사용하는 표준 편차로 설명되는 오류입니다.
일반인이 이 프로세스가 SEM에 대해 의미하는 바를 정확히 말하기 어려울 수 있지만 일반적으로 좋은 설명이면 충분합니다.
모든 오차 막대에 대해 하나의 특정 평균의 신뢰 구간 사용
셋째, 한 특정 그래프에서 오차 막대의 실행 시간은 결과에 대한 기능적 95% 신뢰 구간입니다. 이 데이터는 또한 무엇이 필연적으로 제안되는지 아는 정확도를 보여주지만 이러한 구간은 SEM에 대한 것보다 2배 더 깁니다. .
평균에 대한 안심 구간은 비전문가와 공유하기 어렵습니다. 많은 사람들은 “인구의 의미가 일반적으로 이 범위에 있을 확률이 95%”라고 잘못 생각합니다. 이 진술은 무의미해졌습니다. 모집단 평균이 우리 범위 내에 있거나 그렇지 않습니다. 확률은 게임에 절대 없을 것입니다! “95% 신뢰”라는 단어는 무작위 샘플과 관련하여 실험을 여러 번 반복하고 각 샘플의 신뢰 길이를 계산하도록 합니다.이러한 신뢰 구간의 약 95%에 대한 인구 은행의 실제 이름입니다.
결론
따라서 오류 디스크를 종종 선 그래프 또는 차트의 상단에 오버레이하는 데 사용되는 세 가지 인기 있는 통계가 있습니다. 증명의 표준 편차, 평균의 일반적인 오류는 새로운 95입니다. 포함을 위한 % 신뢰 구간. 오차 막대는 데이터에 대한 근접성 및 특정 평균 추정치의 전체 정확도의 특정 변동을 나타냅니다. 당신이 사용하는 특정한 것은 확실히 당신이 실제로 전달하려고 하는 메시지를 넘어 청중의 호의에 달려 있습니다.
내 추천? 올바른 태도 간격은 잘못 해석될 수 있지만,전문가들은 CLM이 오류 척도 크기(세 번째 다이어그램)를 취하는 가장 좋은 방법이라고 생각합니다.내가 통계 청중에게 말할 때 청중은 귀하의 CLM을 높이 평가할 것입니다. 덜 까다로운 청중을 위해 CLM 확률적 언어 번역에 대해 자세히 설명하지 않고 해당 오류 척도가 “평균의 정확성을 나타냅니다”라고 간단히 말할 것입니다.
다이어그램에서 오차 막대를 얻으려는 데이터 계열을 선택합니다. 차트를 생성하는 경우 차트 요소 추가를 선택한 다음 기타 오차 막대 옵션을 클릭합니다. 오류 표시줄 옵션 탭의 오류 표시줄 서식 양식에서 일종의 오류 금액 섹션에서 Usersky “를 클릭한 다음 ” 값 지정 “을 클릭합니다.
이미 설명했듯이 각 제안에는 고유한 장점과 단점이 있습니다. 대중은 어떤 장치를 만들고 그 이유는 무엇입니까? 의견을 남겨서 생각을 공유하고 싶을 수도 있습니다.
/ * 선택 사항: CLM FWHM 동안 SD, SEM 계산(플로팅에 필요하지 않음) ( 공백 ) /메소드 데이터 proc = Sim noprint; 품질 t; 다르다; 출력 처리 = MeanOut N = N stderr = SEM stddev = SD lclm = LCLM uclm은 UCLM을 의미합니다.도망쳐;ㅏ데이터 요약;MeanOut 정의 (wo = (t ^ =.));CLMWidth는 (UCLM-LCLM) / 2입니다. / * 부분적 CLM 간격 너비 4 . /도망쳐;ㅏ인쇄 데이터 proc = 요약 멍청한 레이블; SD SEM 형식 CLMWidth 6.3; var T SD N SEM CLM폭;다하다;
% 매크로 PlotMeanAndVariation(limitstat =, 레이블 =); 주제 "VLINE 문: LIMITSTAT = & limitstat"; proc sgplot 데이터 = Sim noautolegend; vline t / 응답은 y stat = 평균 limitstat = & 부호 limitstat를 의미합니다. yaxis 레이블은 "& 레이블" = (75 ~ 82) 래스터 값을 의미합니다. 도망쳐;% 를 겨냥하다;ㅏ제목은 단순히 "평균 응답 시간"입니다.% PlotMeanAndVariation(limitstat = STDDEV, 표시 = 평균 +/- 표준 편차);% PlotMeanAndVariation(limitstat은 STDERR과 같음, 레이블 = 평균 +/- SEM);% PlotMeanAndVariation(limitstat = CLM, 레이블 = 평균 및 CLM);이 소프트웨어를 다운로드하여 오늘 컴퓨터의 속도를 향상시키십시오. PC 문제를 해결할 것입니다. 년
Troubleshooting Tips For Standard Error Tracing
Dicas De Solução De Problemas Como Rastreamento De Erro Padrão
Conseils De Dépannage Pour Le Traçage Des Erreurs Standard
Felsökningstips För Standardfelspårning
Sugerencias Para La Solución De Problemas Para El Seguimiento De Errores Estándar
Tips Voor Het Oplossen Van Problemen Voor Het Opsporen Van Standaardfouten
Советы по устранению неполадок при стандартном отслеживании ошибок
Tipps Zur Fehlerbehebung Bei Der Standardfehlerverfolgung
Wskazówki Dotyczące Rozwiązywania Problemów Ze Standardowym śledzeniem Błędów
Suggerimenti Per La Risoluzione Dei Problemi Per La Traccia Degli Errori Standard
년
