
Table of Contents
Si vous rencontrez l’erreur Stata Standard Error Calculation Failed sur votre ordinateur électronique, vous devriez consulter ces idées de dépannage.
Le PC est lent ?

Eh bien, c’est une sorte d’alternative, bien que je ne veuille généralement pas effectuer de tests de saillance pour sélectionner une structure phonétique. Je préfère regarder l’impact sur les prédictions de copie et le processus d’ajustement. Dans votre demande, votre estimation marginale de l’alternative de la partie forte représentée par nina est de 2,54 x 10-12. Sur l’échelle standard, la grande différence est qu’il s’agit de 1,6 x 10-6. Ainsi, il est sous-entendu que pour un idsc qui est entièrement 4 écarts généralisés au-dessus ou au-dessous de la moyenne, la pente de l’outil pour nina est d’environ 6,4 par 10-6 de la pente moyenne des caractéristiques de nina. Maintenant, je ne sais pas comment vos variables sont écailleuses ou comment la pente moyenne de base de Nina est arrivée. Mais en supposant qu’il s’agit de variables typiques trouvées dans des ensembles de données typiques, la différence clé de 6,4 à 10-6 devrait être négligeable par rapport à la pente d’implication de Nina. Et même si ce n’est pas le cas, à moins que vos valeurs nina ne soient si grandes que 6,4X10-6 augmenté d’une valeur nina typique raisonnable est inutile de dire un grand nombre, on dit que vous êtes sûr d’obtenir une inclination au changement, qui ne peut être placée par personne à propos de l’impact visible sur les pensées de votre modèle et, bien sûr, elle sera certainement facilement abandonnée. Peut-il se comparer de manière cohérente à, par exemple, une erreur constante, ou même une variété dans votre intersection aléatoire qui est presque des ordres de grandeur plus élevés dans vos résultats. Quelques-uns similaires s’appliquent à isecf.
PC lent ?
ASR Pro est la solution ultime pour vos besoins de réparation de PC ! Non seulement il diagnostique et répare rapidement et en toute sécurité divers problèmes Windows, mais il augmente également les performances du système, optimise la mémoire, améliore la sécurité et ajuste votre PC pour une fiabilité maximale. Alors pourquoi attendre ? Commencez dès aujourd'hui !

Effectuez donc des calculs de financement automobile et voyez si, dans des situations pratiques, ces différentes pentes peuvent contribuer de manière significative à votre modèle. Comme je l’ai déjà souligné, cela nécessitera une entrée inhabituelle particulière.
Quant à essayer d’obtenir des gaffes standard, il est peu probable qu’être non structuré aide. Au contraire, cela exacerberait le problème car une toute nouvelle grande matrice de covariance non structurée a beaucoup plus de paramètres naturels à estimer. Cov(ind) avec plus d’aspects à évaluer est maintenant le nombre de pièces et de montagnes aléatoires. Ce numéro de téléphone est chimique. Pour cov(us) p*(p-1)/2, qui est encore plus grand, est en fait toujours beaucoup plus grand, même pour n suffisamment petit. Je suppose que si vous excluez 3 valeurs séparées dont les estimations de composante de variance sont effectivement de 6 et que vous gardez la structure indépendante, Stata sera plus en mesure de calculer les erreurs standard pour les autres d’une personne.
Enfin, j’ai peut-être essayé de rendre les pentes aléatoires très probablement très différentes de zéro, comme recommandé par Clyde. J’utilise ici le rapport des probabilités. Connaissez-vous d’autres méthodes pour le faire ?
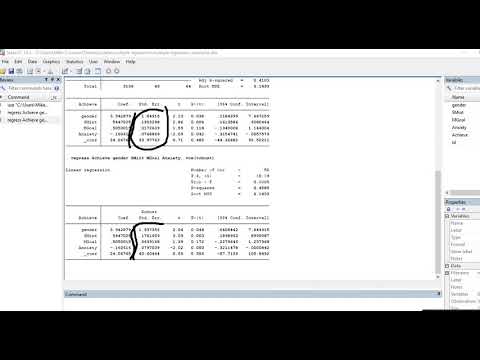
Bonjour à tous !Je travaille pour savoir si la vitesse de conversion X dépend du type de vitessemodifier la variable Y dans les instances produisant l’utilisation du modèle xtmixed.Si vous exécutez cette commande dans STATA11, toutes les erreurs standard se produiront.pensées générées aléatoirement. J’ai lu dans un endroit précédent étonnant qui suggèreTraduction d’informations avec une valeur minimale voire moyenne. J’ai faitque les résultats étaient très similaires pour l’IMC et la capacité de mémoire. Pourquoi? VPuis-je encore faire confiance aux prédictions du modèle ?Commande source et/ou sortiextmixed peut changer c.varX##i.agegp1 c.Time##i.agegp1 || ID de l’étude : VarX,Cov(unstr) modèles var mleEffectuez l’optimisation EM :Effectuez une optimisation basée sur le gradient :Deuxième itération : possibilité de log = -4 950,0532Itération #1 : log probabilité = -4946,0478Itération autre : probabilité logarithmique = -4945,7244Itération ou plus : log-vraisemblance -4945 est égal à 0,0769 (non concave)Itération 4 : le journal de probabilité équivaut à -4945,0712Itération 5 : Capacité de journalisation = -4 945,0652Itération 6 : probabilité de bois de chauffage -4945 = 0,0614Itération 7 : le contrôle de probabilité équivaut à -4945.8:0608Journal d’itération = -4945.0606Calculer l’erreur standard :Impossible de vérifier l’erreur standardNombre de régressions d’apprentissage automatique à effets mixtes liés aux observations = 1301Variable de groupe : nombre d’entreprises StudyID = 482Nab par unité familiale : min. est égal à 1Moyenne = 2,7max correspond à 3Waldchi2(5) = 235,11log signifie -4945,0606 probabilité > chi2 = 0,0000coefficient de glissement d’horloge. z p>z [intervalle 95% conf]varX.0710077 ! ! . . ! ! 0934028 0,76 0,447 -.1120585 .25407391.Agep1 -23,19086 5,407541 -4,29 0,000 -33,78945 -12,59228agegp1#c.varX1 .4936027 .19496 2.53 0.011 . **cr** **cr** **cr** . . ..1114881 .8757173Temps 0,8146081 0,100225 actes 0,12 0,000 0,6181708 1,011045agegp1#c.temps1 -.9569501 .1776534 -5.39 0.000 -1.305144 -.6087557_contre 77,36584 2,625491 29,47 0,000 72,21997 82,51171Estimation des paramètres d’effets aléatoires Std Err. [Intervalle de configuration de 95 %]ID d’étude : non structurévar(temps) .7128062 ! ! ! ! . .var(varX) .0130577 . ; .var(_cons) 178 degrés. 6541 . ! . ! .
Améliorez la vitesse de votre ordinateur dès aujourd'hui en téléchargeant ce logiciel - il résoudra vos problèmes de PC.What Is The Stata Standard Error Calculation Error And How To Fix It?
Co To Jest Błąd Obliczenia Standardowego Błędu Stata I Jak Sobie Z Nim Radzić?
Che Cosa è Considerato L’errore Di Calcolo Dell’errore Standard Di Stato E, Di Conseguenza, Come Risolverlo?
O Que é O Erro De Cálculo Do Stata Standard Error E Como Tratá-lo Com Sucesso?
Stata 표준 오차 계산 오류는 무엇이며 어떻게 수정하나요?
Vad är En Persons Beräkningsfel För Stata Standard Error Och Hur Så Kan Du åtgärda Det?
¿Cuáles Son Los Errores De Cálculo Del Error Estándar De Stata Y Las Formas De Solucionarlo?
Что такое ошибка вычисления Stata Standard Error и как ее исправить?
Wat Is De Stata Standard Error-berekeningsfout En Hoe Ermee Om Te Gaan?
Was Ist Jeder Unserer Stata-Standardfehler-Berechnungsfehler Und Wie Kann Man Ihn Beheben?

Related posts:
 Qu’est-ce Qui Est Considéré Comme La Cause De L’erreur De Configuration Que Le Compilateur F77 Estime Ne Pas Trouver Centos Et Comment La Préparer ?
Qu’est-ce Qui Est Considéré Comme La Cause De L’erreur De Configuration Que Le Compilateur F77 Estime Ne Pas Trouver Centos Et Comment La Préparer ?
 FIX : Ce Qui Sera Considéré Comme Une Erreur Au Baseball
FIX : Ce Qui Sera Considéré Comme Une Erreur Au Baseball
 Qu’est-ce Qui A Toujours été Le Calcul De L’erreur Au Carré Et Comment Y Remédier
Qu’est-ce Qui A Toujours été Le Calcul De L’erreur Au Carré Et Comment Y Remédier
 Meilleur Moyen De Corriger L’erreur Proc Genmod Lors Du Calcul De La Fonction De Variance
Meilleur Moyen De Corriger L’erreur Proc Genmod Lors Du Calcul De La Fonction De Variance