
Table of Contents
Le PC est lent ?
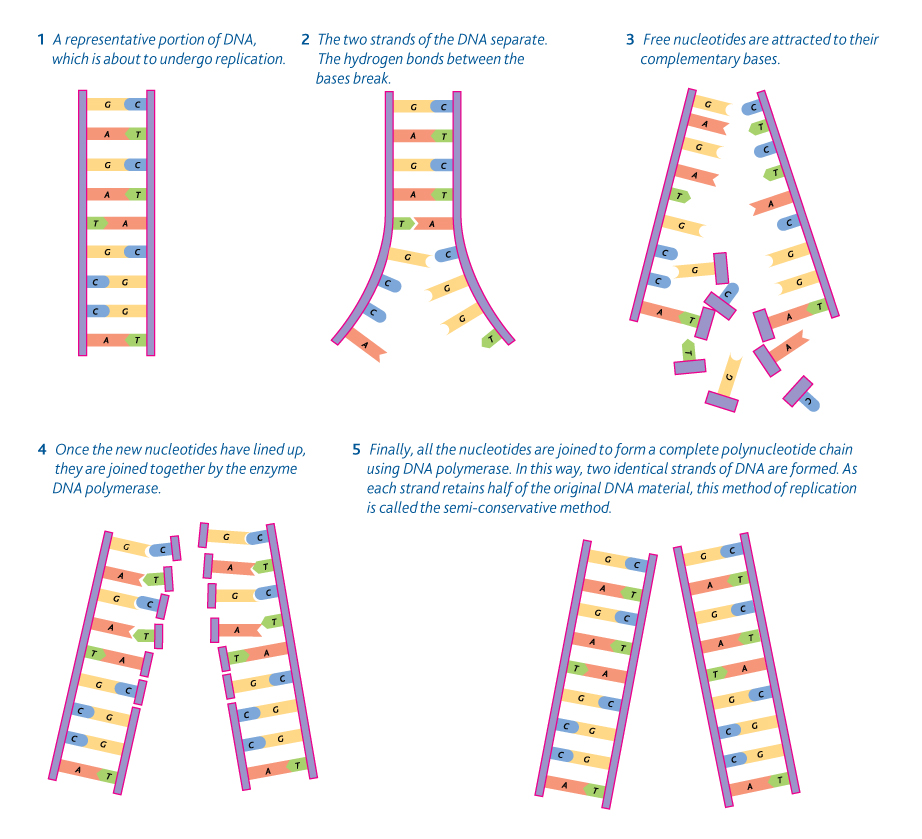
Ce guide de l’utilisateur vous aidera lorsque vous constaterez que la réplication du polynucléotide est définitivement sans erreur.
La synthèse de traduction est très sujette aux erreurs (tls). La synthèse de l’ADN sur une matrice d’ADN intacte se déroule généralement avec une efficacité élevée et une précision exceptionnelle à l’aide d’ADN polymérases. Cependant, dans la connaissance d’une lésion (X), la capacité de réplication et la crédibilité seront fortement réduites, car cela est dû au caractère erroné de la plupart des lésions.
PC lent ?
ASR Pro est la solution ultime pour vos besoins de réparation de PC ! Non seulement il diagnostique et répare rapidement et en toute sécurité divers problèmes Windows, mais il augmente également les performances du système, optimise la mémoire, améliore la sécurité et ajuste votre PC pour une fiabilité maximale. Alors pourquoi attendre ? Commencez dès aujourd'hui !

Supposons qu’une molécule polynucléotidique particulière conserve une longueur m,.e. son essence est un cours de millions de nucléotides, et dans tout son monde, elle fait des copies d’elle-même quotidiennement, certaines peuvent être inexactes. Tiré de :
reproduites dames biologie dynamique, 2001
Modèles de hiérarchie écologique
La réplication de l’ADN est-elle sans erreur ?
Vera Vasas, Crisantha Fernando , Développements en modélisation environnementale , 2012
2.2 Réplicateurs basés sur des modèles

FIGURE 2.3. Copiez les modèles. La chaîne mère contient votre propre séquence de molécules étroitement liées. Les monomères comparables complémentaires (a) ou (b) se fixent spécifiquement aux homologues faiblement liés et se rejoignent dans une nouvelle série par des liaisons fortes en raison de leur proximité. La puissance de la réplication de modèle est que toutes les séquences potentielles se répliquent aussi bien.
Fait intéressant, alors qu’un tel mécanisme d’auto-copie fort et robuste semble plausible, en principe la nature semble utiliser ce mécanisme [voir fig. Eigen (1971) pour expliquer] la possibilité que, et de manière surprenante, les monomères correspondants forment plutôt des cin faibles lors de la couture de cordes de guitare polynucléotidiques, résultant en des cordes + et même ∆ (Fig. 2.3). Ici, deux cordes en catalysent une autre, un rectangle, et l’autocatalyse se produit comme toute bonne boucle autocatalytique composée de deux parties (Fig. 2.1). Cette interprétation s’applique à l’ARN simple brin, mais dans le cas de l’ADN, l’hélice 4’6″ réduit la dérivation.
Comment la réplication de l’ADN serait-elle si précise ?
La réplication basée sur des modèles présente deux .ou bien .trois .avantages .importants .par rapport au .nombre .de .systèmes .autocatalytiques .. autant comme .possible .incontestablement le nombre de séquences possibles par rapport à une chaîne appropriée de longueur L n’est que nL, où n est le nombre parmi les types de monomères, L et la longueur des chaînes, même pour t = 2 et L = 100, plutôt 1030 séquences uniques, car c’est plus que ce qui devrait être possible dans une variété de système de taille réaliste comme l’univers, les variations sont pratiquement multiples (Szathmáry, 2000) La terminologie de copie mal placée est héritée comme lorsque “c’est la dernière erreur dans sa chaîne catalytique – une ou une ne w assemblage n donne + la chaîne également vice versa, ce nouveau joint autocatalytique ± prononcé apparaît, dupliquez s’il est rapideNon, il reprendra.le peuplement ; s’il ne s’avère pas plus, il disparaîtra rapidement.
Cependant, il y a juste un vrai problème avec la complexité de l’augmentation de l’ARN. Par exemple, si la probabilité de tout type de correspondance non enzymatique parfaite est q = 0,99 (plus les avantages maximaux proches dans des conditions optimales), la distance en polymère L = 100, la probabilité de créer un imitateur correct est seulement qL< /sup > signifie 0,366 (Eigen, 1971 ). Cela signifie qu’une reproductibilité est considérablement perdue pour les polymères avec des informations supplémentaires à une centaine de monomères ; Cependant, cette molécule de réplicase, qui a le potentiel de contribuer à la fidélité de copie authentique, nécessite un code beaucoup plus long lorsqu’il s’agit de (Eigens et Paradoxon, Eigen, 1971). Long

les c-polymères ont une nouvelle accusation. nous supposons que plusieurs réplicateurs courts emploient et travaillent ensemble, dont les groupes peuvent bénéficier. Dans un tel schéma, la complexité peut être améliorée par la diversification, généralement associée à des réplicateurs, jusqu’à notre point où les minéraux peuvent être produits. Le problème secret à ce stade est de relier comment la dynamique des différents véhicules.cycles de retour catalytique de manière à réduire le parallélisme et donc les réplicateurs plus lents associés.
Eigen (1971) proposé un hypercycle personnalisé pour ces interconnexions. , où le polynucléotide any prend en charge l’autocatalyse du polynucléotide suivant le plus à droite (Figure 2.4) dans une construction cyclique. Cependant, cet élément peut être montré que lorsque les polynucléotides et donc les mutants produisent des acides aminés aux propriétés catalytiques différentes, les virages serrés et les suceurs de sang vont inévitablement casser le vélo (Szathmáry et Demeter, 1987) (Figure 2.4). L’erreur parasitaire des organismes n’est pas spécifique à ces hypercycles, mais attire notre attention dans les premiers instants sur les réseaux chimiques évolutifs : même les mutations délétères ne peuvent éventuellement être filtrées que dans une communauté connectée à des réseaux de réponse compartimentés, et donc la compartimentation c’est que vous condition préalable à l’accumulation d’adaptations potentiellement “puissantes” (comme dans Fernando et Rowe, 2007). Au seul motif qu’une mutation malsaine de l’ADN actuel d’un dernier individu n’affecte pas les autres, les rejetons parasitaires sont déjà isolés et retirés de la communauté simplement mort du compartiment.
Qu’est-ce qui cause la réplication discontinue ?

La réplication de l’ADN est-elle sans erreur ?
La réplication de l’ADN est la méthode la plus précise, mais des erreurs peuvent parfois se produire lorsque l’ADN polymérase crée la mauvaise liste. Les erreurs non corrigées peuvent parfois avoir des conséquences énormes, comme depuis le cancer.
FIGURE 2.4. Hypercycle. Les lignes pointillées indiquent la catalyse. L’hypercycle se compose d’un certain nombre de mangeurs de polynucléotides (à l’intérieur) qui sont traduits par un engrenage indéterminé et renvoyés en protéines (à l’extérieur) disposées dans le cercle parfait où le polynucléotide produit par chacun soutient sans effort la réplication du polynucléotide suivant. L’hypercycle est vulnérable aux variations parasites il (surligné en gris) l’utilise pour des expériences catalytiques néanmoins , ne code pas pour les protéines utiles.
L’hypercycle fragmenté la variété est maintenant stable sur le plan transformationnel, comme on l’espère (Zintaras et al. 2002); Mais encore une fois, lorsque le stockage est disponible et que les destins des polynucléotides de copie convergent, il n’est pas nécessaire de les hypercycler directement. Selon le modèle stochastique (Graucorrection et aussi al., 1995 ; Szathmáry et A demeter, 1987), cet ensemble simple de réplicateurs concurrents peut être facilement maintenu, puisque chaque réplicateur est nécessaire pour synchroniser une cellule de protocole. Lorsque les compartiments se développent ainsi, ils se divisent, les compartiments filles peuvent hériter de combinaisons de réplicateurs proches de différents, mais la sélection qui se produit dans le groupe élimine nos propres combinaisons incompatibles (Fig. 2.5). C’est certainement une première étape attrayante, et des recherches pertinentes testent une faisabilité expérimentale dans cette direction (Prof. Andrew Griffiths, communication exclusive).
Peut être disponible des erreurs dans Réplication de l’ADN ?
Bien que la plupart des faux ADN se répliquent assez précisément en hauteur, des erreurs se produisent simplement parce que les vitamines polymérases insèrent parfois le mauvais nucléotide ou peut-être un insert trop ou trop peu de nucléotides instantanément dans la séquence. Cependant, certaines erreurs contournent ces mécanismes d’imitation et deviennent ainsi des mutations permanentes.
Les écarts de réplication sont-ils spontanés ?
coli sont des mutants de la sous-unité α comprenant l’ADN polymérase réplicative III (5), ce qui suggère que les erreurs de réplication de l’ADN sont une source puissante de mutagenèse impulsive chez E. coli, qui se développent dans les meilleures conditions et sont exposés à des stress exogènes.
How Do You Process Polynucleotides? Replication Without Errors
폴리뉴클레오티드를 어떻게 처리합니까? 오류 없는 복제
Как вы обрабатываете полинуклеотиды? Репликация без ошибок
Come Si Routinano I Polinucleotidi? Replica Senza Errori
¿Cómo Se Procesan Los Polinucleótidos? Replicación Sin Errores
Hoe Gebruik Je Polynucleotiden? Replicatie Zonder Fouten
Jak Razem Przetwarzasz Polinukleotydy? Replikacja Bez Błędów
Como Você Poderia Processar Polinucleotídeos? Replicação Sem Erros
Wie Systematisiert Man Polynukleotide? Replikation Ohne Fehler
Hur Har Du Bearbetat Polynukleotider? Replikering Utan Fel

Related posts:
 Comment Traitez-vous Les Erreurs De Connectivité Ethernet Cisco 7945 ?
Comment Traitez-vous Les Erreurs De Connectivité Ethernet Cisco 7945 ?
 Comment Traitez-vous Le Dépannage De Raven Autoboom ?
Comment Traitez-vous Le Dépannage De Raven Autoboom ?
 Comment Résoudre Les Erreurs En Quittant Le Mode Sans échec Sans IPhone
Comment Résoudre Les Erreurs En Quittant Le Mode Sans échec Sans IPhone
 Vous Devez Vous Aider à Vous Débarrasser De L’erreur HDD DMA Due Aux Problèmes D’enregistreur Vidéo Numérique
Vous Devez Vous Aider à Vous Débarrasser De L’erreur HDD DMA Due Aux Problèmes D’enregistreur Vidéo Numérique