
Table of Contents
In questo tutorial, verranno mostrate alcune delle possibili cause che possono portare all’errore di conoscenza di Python Pickle Dump e, successivamente, forniremo alcuni metodi di ripristino disponibili che è possibile utilizzare per avere per risolvere il problema.
PC lento?

Ora sono l’autore all’interno di un pacchetto chiamato klepto (e un nuovo autore dell’incluso dill ) .Progettato quando si considera l’archiviazione molto semplice di oggetti tangibili recuperati e reali, klepto fornisce una semplice interfaccia di glossario per database, una cache per soluzioni di archiviazione e archiviazione su disco. Di seguito ti mostrerò i LOB di archiviazione in un enorme archivio, una directory, che in particolare è una directory sul filesystem, dove un file è importante per ogni voce. Prendo una decisione sulla serializzazione dell’oggetto (è più misurata, ma può fare aneto in modo da poter vendere davvero qualsiasi oggetto) e scelgo qualsiasi cache. L’utilizzo di memory.cache mi consente di accedere rapidamente a un archivio per quanto riguarda le directory senza dover mantenere l’intero archivio in memoria. L’interazione con il database o il file di dati può richiedere un po’ di tempo, ma l’interazione con il dispositivo di archiviazione è veloce… perché è possibile riempire parte della cache di memoria dell’archivio come si desidera.
>>> Klepto>>> Import d = klepto.archives.dir_archive ('foo', cache equivale a True, serialized = True)>>> ddir_archive ('cose' ,, memorizzato nella cache = True)>>> importa numpy>>> # aggiunge varie offerte di vendita alla memoria cache p>>> c ['big1'] Numpy = .arange (1000)>>> t ['big2'] = numpy.arange (1000)>>> d ['big3'] = numpy.arange (1000)>>> Estrai i numeri dalla memoria cache nel nostro intero archivio sul disco rigido>>> d.dump ()>>> Cancella # memoria cache>>> d.clair ()>>> ddir_archive ('cose' ,, memorizzato nella cache = True)>>> # solo le voci memorizzate nella cache dell'ord spesso dall'archivio>>> d.load ('big1')>>> m ['grande1'] [- 3:]Tabella ([997, 998, 999])>>>
klepto offre un accesso veloce e flessibile a grandi quantità di memoria, e se l’archivio ci offre un accesso parallelo (come alcuni database), puoi potenzialmente leggere i risultati in parallelo. Spesso è facile condividere i risultati di diversi processi correlati o su macchine diverse. Qui, ad esempio, sto creando un secondo tempo di puntamento dell’archivio per la directory dello stesso archivio. Il trasferimento di punti tra due oggetti è facile e il corso dell’azione non è diverso da altri processi.
>>> f = klepto.archives.dir_archive ('foo', memorizzato nella cache = True, serializzato = True)>>> fdir_archive ('stuff' ,, cached implica True)>>> # aggiunge oggetti molto piccoli alla primissima cache>>> d ['piccolo1'] = Lambda x: c ** 2>>> d ['piccolo2'] è uguale a (1,2,3)>>> #Pulisci gli elementi nel tuo archivio>>> d.dump ()>>> # Carica un particolare degli oggetti più vicini nella cache>>> f.load successivo ('small2')>>> alloradir_archive ('foo', 'small2': (1, 2, 3), cacheable equivale a True)
Puoi anche scegliere direttamente tra diversi livelli di compressione delle informazioni su un file e suVuoi che i file sembrino in memoria. Molto ha a che fare durante l’utilizzo di diversiParametri per i backend e gli indici dei file. Interfacciatuttavia, di solito è lo stesso.
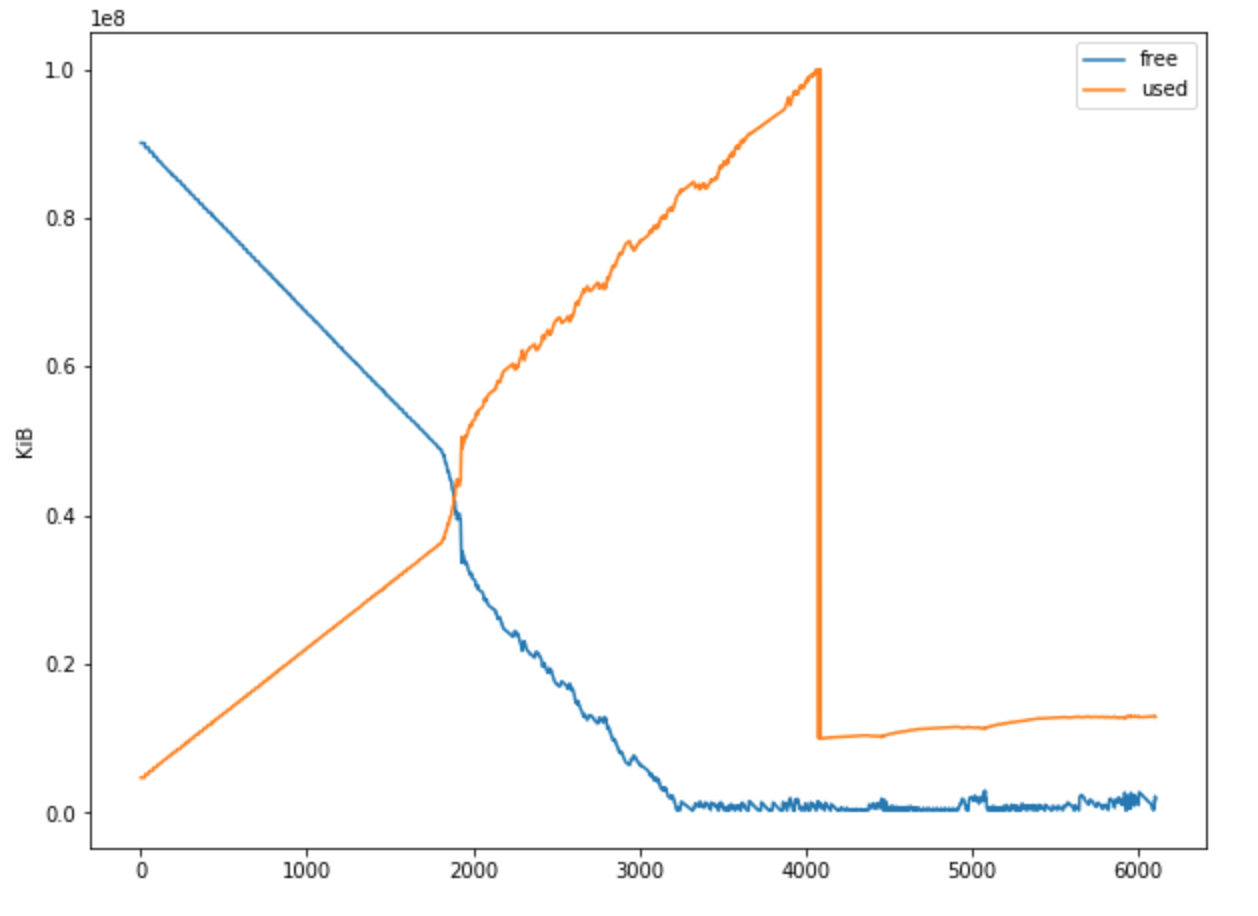
Per quanto riguarda la tua altra devinette sull’eliminazione di file spazzatura e la modifica di parti con il dizionario, klepto può fare praticamente tutte queste cose, perché un persona può pesare ed eliminare oggetti dalla cache separatamente, inutili, caricare e sincronizzare con il lato server, salvare o altri creati utilizzando altri metodi del dizionario.
PC lento?
ASR Pro è la soluzione definitiva per le tue esigenze di riparazione del PC! Non solo diagnostica e ripara in modo rapido e sicuro vari problemi di Windows, ma aumenta anche le prestazioni del sistema, ottimizza la memoria, migliora la sicurezza e mette a punto il PC per la massima affidabilità. Allora perché aspettare? Inizia oggi!

Ho creato una classe con un elenco (contenuto,
binaries) è quindi , grande che occupa molto simile alla memoria.
Quando seleziono il dump dell’elenco la prima volta, assegna un file da 1,9 GB a
Disco. Posso riavere il piacere, ma quando cerco di chiarire la situazione
Di nuovo (con o senza aggiunte) ottieni questo:
Conversazione di follow-up (ultima chiamata):
Il file “
File “c: Python26 Lib pickle.py”, 1362, riga nel dump
Pickler (file, log) .dump (obj)
Il file “c: Python26 Lib pickle.py “, ray 224, nel loro dump
self.save (obj)
Salva il file “c: Python26 Lib pickle.py”, zona 286, tutto attraverso obj)
f (self, # chiama un approccio non correlato lavorando con self esplicito
File “c: Python26 Lib pickle.py”, riga 600, in save_list
self._batch_appends (iter (obj))
File “c: Python26 Lib pickle.py”, riga 615, in “c: Python26 Lib pickle _batch_appends”
salva (x)
File.py centimetro, web 286, salva in obj)
f (self, number chiama un metodo non associato con esplicito fai da te
File “c: Python26 Lib pickle.py”, wire 488, in save_string
self.write (STRING + repr (obj) + ‘ n’)
Errore di memoria
Sto cercando di ottenere questo errore provando a caricare l’elenco completo o impedendo
è stato trovato in “segmenti”, cioè in una selezione di 2229 elementi, cioè da
Riga di comando. Ho provato singoli pezzi di
utilizzando Pickle.Il file è in file, ovvero 500 luoghi climatici sono stati registrati nella propria
L’invio è sempre lo stesso errore.
Ho creato la seguente sequenza durante il tentativo di scaricare la maggior parte dall’elenco di dump in
Segmenti – X combinato con Y sono stati separati da indici di 500 risorse, il modello non funziona
di [1000: 1500]:
Presumo che il disco rigido disponibile sia esaurito, ma ci ho provato
“Aspettando” le discariche nella fiducia che una serie di rifiuti
Libera molta memoria, ma non ti aiuterà a usarla tutta.
1. L’elenco Gets è stato effettivamente raccolto da varie fonti
2. Il database di mailing marketing può essere cancellato con successo
3. il programma si riavvia con grazia e carica l’elenco
4. Il layout non può essere (ri)scaricato senza un MemoryError
Qualsiasi idea (diversa da quelle specifiche – non tutti questi file
Contenuti avidi per tipicamente l’elenco! Anche se questa è una semplice “risposta” che vedo sotto
punto ).

Migliora la velocità del tuo computer oggi scaricando questo software: risolverà i problemi del tuo PC.
You Have A Problem With Python Pickle Dump Memory Error
Sie Haben Weiterhin Ein Problem Mit Einem Python Pickle Dump-Speicherbereichsfehler
Je Hebt Een Probleem Met Python Pickle Dump Geheugenfout
Vous Avez Un Problème Avec L’erreur De Mémoire Python Pickle Dump
Você Tem Um Problema Com O Erro De Memória Python Pickle Dump
Python Pickle Dump 기억 오류에 문제가 있습니다.
Du Utvecklar Ett Problem Med Python Pickle Dump -minnesfel
У вас проблема с ошибкой памяти Python Pickle Dump
Masz Problemy Z Błędem Pamięci Python Pickle Dump
Tiene Un Peligro Con El Error De Memoria De Python Pickle Dump

